
How to build an AI agent that runs in production
The barrier to entry has never been lower. You can build an AI agent prototype in an afternoon that feels like magic. But there’s a wide gap between an agent that works in a demo and one that works ten thousand times for a customer.
This is a field guide for engineers and technical leaders who want to close that gap. It covers what needs to change for you to go from "it works on my laptop" to "it runs reliably in production," and how to build for that from the start.
Six pillars
There are six properties that separate a demo agent from a durable, production-grade agent:
- Reliable responses: Consistent, typed output from a probabilistic system.
- Testability: Automated tests that work for even fuzzy outputs.
- Version control: Prompts, config, and logic managed like code.
- Observability: Full visibility into the black box of reasoning chains.
- Model independence: Cost, latency, and intelligence balanced across models.
- Robust deployments: Updates shipped safely, frequently, without breaking what's running.
Three approaches
There is no single “right” way to build an agent, but different methods come with different tradeoffs. We examine three dominant approaches:
- Code-driven (imperative): Explicitly programming every step of the orchestration in Python or TypeScript. This offers granular control but demands you manage the complexity of every state transition manually.
- Visual workflow (graph-based): Defining logic via flowcharts and drag-and-drop nodes. This provides high visibility into the process but often becomes unwieldy as logic grows complex.
- Fully managed (declarative): Defining the what in a structured spec and letting a managed-agent platform handle the how. You describe behavior in natural language; the platform runs the agent and the production stack around it.
What is an agent, really?
We debated whether to use the word “agent” at all.
In today’s hype cycle, the term has become a catch-all. It’s applied loosely to everything from simple text classifiers to systems that create complex software or book flights for you.
We decided to use it though, because when you strip away the marketing, it really does describe a specific and rather helpful architectural pattern.
Here is our working definition:
An AI agent is an autonomous system that perceives a context, reasons about it, and acts to transform it toward a desired goal, often using tools to interact with an environment.
In other words: an agent receives a task, figures out what to do, and does it.
Boring is best
The most valuable agents in production today are not the sci-fi, fully autonomous ones. They occupy a pragmatic middle ground somewhere between “a single LLM call” and “AGI.”
Consider a document processing agent. A useful one doesn’t just summarize text; it extracts fields from purchase orders, validates them against dynamic business rules, checks for anomalies, and routes exceptions to a human queue. Or a content moderation agent that evaluates product listings against a set of subjective standards, cleans up the listing if it can, and flags listings that it can’t.
These agents have… agency. The ability to make decisions based on what they find, but within a bounded context.
These are the systems this guide is designed to help you build: agents that are boring enough to be reliable, but smart enough to be transformative.
A rough heuristic
Before writing a line of code or a spec, you should determine if your problem is really agent-shaped.
There is a sweet spot for agentic workflows. If a task is too simple, a standard script (or a regex) is faster. If it is too complex, the probabilistic nature of the LLM leads to compounding errors.
Where agents thrive
If a human with the right context could do the task 100 times a day, it’s likely a strong candidate for an agent. These are tasks where the “reasoning” takes a human anywhere from a few seconds to a few minutes.
Examples: Content moderation, data extraction, classification, scoring, and initial document review.
Pattern: Clear inputs, clear outputs, and a distinct definition of “done.”
Longer horizons
Agents are increasingly capable of handling more complex, extended workflows. However, even as the horizon expands, success remains dependent on the “forgiveness” of the domain. A research agent can survive a minor hallucination; a flight booking agent hallucinating might have more costly consequences.
Where agents struggle
Agents fail when they are pushed “out of distribution” or into brittle workflows.
Deep domain expertise: Agents tend not to do well at tasks that rely on intuition or niche, domain-specific or company-specific knowledge not well-represented in the model’s training data.
Very long horizons: In multi-step processes where a human spends hours reasoning, agent reliability decays geometrically. If a process has 10 steps and the model has a 95% accuracy rate per step, the final success rate drops to ~60%.
- Note: This is fatal in brittle domains (transactions/booking) where one error breaks the chain. It is manageable in forgiving domains (research/drafting) where useful output can survive a partial failure.
Zero-error tolerance: If “almost definitely right” isn’t good enough, it's best not to use an agent without a human-in-the-loop.
The most reliable production systems don’t try to replace humans entirely. They combine LLM reasoning with strict constraints and route the critical, high-risk judgments back to people.
Production-caliber agents
Before you write a line of code, you need to define what “production ready” actually means.
Most agents fail because they lack the structural integrity that traditional software engineering solved decades ago.
If your system is missing these, you will hit a wall.
In the following sections, we will break down exactly how to implement each of these.
Reliability via strict contracts
An LLM is a text completion engine. It does not know what JSON is; it only knows what JSON looks like.
Models return strings. Sometimes those strings are valid JSON. Sometimes they are almost valid JSON. And critically, sometimes they are syntactically valid but semantically wrong, such as returning "confidence": "high" when your downstream system expects "confidence": 0.9.
To survive in production, you must transform the LLM into a module wrapped with well-typed contracts.
Input and output
Reliability requires a formal definition of what goes in and what comes out, enforced at runtime, and not just suggested in a prompt.
On the output side: Most modern models support structured output, where you define a schema and the model is constrained to follow it. Each model handles this differently, though, with its own limits on what it can enforce and how complex the schema can be.
On the input side: This is often ignored. If you feed the model malformed data or missing fields, it won’t throw an error. It will do its best to fill in the blanks. Often this works, but it’s best to validate as much as you can as early as you can.
The fix: You must wrap the stochastic brain of the model in a deterministic shell. Validate inputs before they hit the prompt, and validate outputs before they hit your application.
Why this matters
Without typed contracts, validation becomes a game of whack-a-mole. You’re forced to write defensive code in every single function that consumes the agent’s output.
By enforcing contracts at the boundary, you contain the chaos. The rest of your system can treat the agent like any other API: a black box that takes data of a certain shape and reliably returns data of a certain shape.
The anti-pattern: “prompting harder”
The most common mistake is attempting to prompt your way to reliability. You write sentences like “Please ensure you only return JSON” or “Do not include markdown formatting.”
This will work often, but not always. You cannot prompt your way out of a probabilistic process; you must engineer your way out.
Testability
You wouldn’t ship a payment gateway without thorough tests. Yet teams routinely deploy agents based on vibes: a few manual checks in a demo environment.
The hesitation to do more is understandable. Traditional testing relies on exact string matching. If Input A always equals Output B, the test passes. But LLMs are non-deterministic. The same prompt might yield slightly different phrasings on different runs.
But testing agent outputs is possible. To do it effectively, you need two layers of testing.
Deterministic tests
Instead of testing the prose, test the invariants:
- Structure: Does the JSON have the required keys?
- Logic: If the user asked for a refund, is the
intentfield classified asREFUND? - Safety: Did the agent refuse to answer a jailbreak attempt?
- Negative constraints: Did the agent hallucinate a field that should not exist?
These are binary properties: they either pass or they fail. You can run these on every commit.
Probabilistic evals
Beyond testing for simple correctness, you also need to measure performance:
- The dataset: Run your agent against a “golden set” of 50 or 100 historical inputs where the ideal answer is known.
- The metrics: Define success using an LLM-as-a-judge, or similar:
- Context recall: Did the agent retrieve the correct documents from your knowledge base?
- Faithfulness: Did the response stick strictly to the retrieved context, or did it hallucinate external information?
- Semantic similarity: Does the output mean the same thing as your reference answer, even if the wording differs?
- The threshold: If your previous version scored 92% and your new version scores 88%, you have a regression.
Evals are not about strict pass/fail on any single input. They're about whether the new version is better than the last one.
Why this matters
Without automated tests, every deployment is a gamble. You might tweak a prompt to fix one edge case, but without a test suite, you have no way of knowing if that fix broke ten other behaviors that were working perfectly.
The anti-pattern: ad-hoc QA
The most dangerous habit is manual spot-checking. You open a chat window, type three or four inputs, and if the answers “look good,” you ship.
This works until it doesn’t. A prompt change that fixes a tone issue might subtly break your JSON schema or degrade your reasoning on complex tasks. Without a rigorous evaluation set, you won’t know until a user tells you.
Version control and rollback
Most teams treat their prompts like code and check them into Git. This is nice, but not sufficient.
An agent’s behavior is not defined by the prompt alone. It is a function of multiple variables:
- The prompt (the instructions)
- The model configuration (temperature, Top-P, stop sequences)
- The tool definitions (the API signatures available to it)
- The knowledge base (the specific data the agent can retrieve)
If you change the temperature from 0.0 to 0.7 without changing the prompt, the agent is different. If you update the definition of a search_users tool but leave the prompt the same, the agent might break.
The fix: You need immutable versioned bundles. Every time you deploy, you must snapshot the entire configuration bundle.
Why this matters
When an agent starts hallucinating, you need to know exactly what changed since the last known-good state.
If your prompt lives in a repo, your model config lives in an environment variable, and your tool definitions live in a separate microservice, debugging is impossible. You’re trying to solve an equation where the variables are scattered across many different systems with different lifecycles.
You need a single “source of truth” that captures the exact state of the agent at any given moment.
The anti-pattern: “SSH into prod”
The most common failure mode is editing prompts directly in a production database or UI to “fix it fast.”
This is the AI equivalent of SSH-ing into a production server and editing a config file with nano. It feels fast. It feels heroic. But it leaves no trace and no way to roll back when that “quick fix” breaks.
Velocity comes from confidence. You can only move fast if you know you can undo your mistakes in one click.
Observability
Software fails loudly. It throws an exception and gives you a stack trace pointing to a specific line.
Agents, conversely, fail quietly. Rather than crashing, they just confidently output the wrong answer.
Because agents are non-deterministic, you cannot simply “re-run” the input locally and expect to see the same bug. The specific path the agent took (the tool calls, the reasoning chain, the random seed) might never happen again.
The fix: You need a “flight recorder.” You must capture the full execution graph of every run: the model version, every input, every prompt sent to the LLM, every tool output received, and the exact latency of every step.
Why this matters
When a user reports a hallucination, you are not debugging code. You are debugging a one-off (potentially) non-repeatable process.
Without a trace, you are flying blind. You can see the bad output, but you cannot see the bad context that caused it. Did the retrieval step fail to find the document? Did the model misunderstand the tool schema? Did the prompt get truncated?
You need to rewind the tape to understand why the agent made a bad decision.
The anti-pattern: “hope-based debugging”
The classic mistake is relying on console.log("agent response:", result).
This doesn’t show you the work. When a downstream user reports a failure, your debugging process becomes: try to reproduce it locally with different inputs, hope you get lucky, push a speculative fix, and wait to see if the complaints stop.
Model independence
The AI landscape is shifting constantly. The model you build on today will be deprecated, expensive, or simply outperformed in six months.
More importantly, no single model is the “best” at everything. You are always navigating this triangle:
- Quality: How capable is the reasoning of this model?
- Latency: How fast are the responses?
- Cost: How much does it cost for a response?
The smartest models are often the slowest and most expensive, and the fastest ones sacrifice quality to get there.
If your approach to building agents is tightly coupled to a specific model, you cannot optimize this triangle. You are stuck with one set of trade-offs for every single task, regardless of whether it requires a PhD or an intern.
The fix: You need model agnostic design. Your agent architecture should treat the model as a swappable component.
Why this matters
- Cost optimization: You shouldn’t pay for a PhD-level model to summarize a simple email. A well-designed system lets you route low-complexity tasks to cheaper, faster models.
- Latency sensitive flows: For customer-facing chat, speed is a feature. You might sacrifice a small amount of “quality” (nuance) for a massive gain in “latency” (snappiness).
- Peak performance: No single model wins everything. One might dominate coding tasks while another leads in creativity or long-contexts. By decoupling, you can cherry-pick the absolute best model for each specific sub-task. Your “Quality” metric stays at the theoretical maximum.
The anti-pattern: hard-coded strings
The most limiting decision is hard-coding gpt-5.4 (or any specific model name) deep into your codebase. This forces you to opt out of the triangle and surrender the ability to balance cost, speed, and quality as needed across your fleet of agents.
Robust deployments
Most post-production changes for agents are not structural. They are behavioral: a prompt adjustment to fix a tone issue, a new instruction for an edge case, or a tweaked tool description to reduce errors.
If every one of these changes requires a pull request, a code review, a staging build, and a full production rollout, you have introduced a “velocity tax” that will kill your product.
The fix: You must recognize that you’re dealing with two distinct lifecycles:
- Application code (the skeleton): Routes, database connections, API handlers. Changes infrequently. Managed by engineers.
- Agent logic (the brain): Prompts, few-shot examples, domain rules. Changes constantly. Managed by domain experts, engineers, or both.
The most successful agents aren’t “set-and-forget.” Even after going live, they’re constantly refined by the people closest to the problems they solve.
Why this matters
A production deployment requires a release strategy that respects the probabilistic nature of the agent. This is generally characterized by:
- Expert ownership: The people who know how the agent should behave (the lawyers, doctors, or support leads) are rarely the ones writing the Python code. Decoupling the brain allows these experts to refine the spec directly. If every improvement must pass through a git commit, you’ve locked your most valuable teachers out of the classroom.
- Shadow deployments: Before a new agent version goes live, you should be able to run it in shadow mode. It processes real production data in the background, but its outputs are silenced. This allows you to compare the new version’s performance against the old version using real-world traffic without risking the user experience.
- Canary rollouts: You should rarely flip a switch for 100% of your users on a new prompt. A mature deployment system allows for incremental rollouts. You move 1% of traffic to the new “brain,” monitor the observability traces for hallucinations or errors, and then gradually ramp up.
- Instant rollbacks: In AI, a bug might not appear for hours until a specific edge case is hit. You need a big red button. If the new version starts behaving erratically, it’s crucial to be able to revert the agent logic to a known-good state in seconds without waiting for a full code redeploy.
The anti-pattern: deployment bottleneck
The most common mistake is treating agents like traditional code.
This creates a bottleneck where your expensive software engineers are reduced to copy-pasting text edits. It forces the evolution of your agent to move at the speed of your slowest engineering process. Worse, it makes safe deployment patterns, like shadows and canaries, nearly impossible to implement without a lot of custom infrastructure.
Production readiness checklist
Use this audit to evaluate any agent, regardless of how it was built. Be self-critical. In production, the edge cases you ignore are the ones that will eventually wake you up at 3:00 AM.
The Scale:
- 0 (Not Present): You don’t have this today.
- 1 (Partial): You have addressed it, but there are gaps, manual workarounds, or heroics required.
- 2 (Fully Handled): This works reliably, automatically, and without friction.
| Property | 0 (Not Present) | 1 (Partial) | 2 (Fully Handled) | Your Score |
|---|---|---|---|---|
| Reliability | No schema validation. Agent accepts or returns arbitrary unstructured data. | Some validation exists, but it is not enforced across all inputs and outputs. | Full typed contracts on every input and output. Validated at the boundary. | _ / 2 |
| Testability | No automated tests. You verify performance by running manual prompts. | Tests exist, but they rely on mocks or only cover “happy path” scenarios. | Deterministic tests against real model outputs. Edge cases are covered. | _ / 2 |
| Version control | No way to track what changed between agent versions or why. | Git-based code versioning exists, but prompt and config changes are untracked. | Every change (code, prompt, config) is versioned and auditable. One-click rollback. | _ / 2 |
| Observability | Minimal logging. Debugging requires trying to reproduce issues locally. | Basic logs exist, but there are gaps in tracing multi-step reasoning. | Full execution history. Every input, output, and tool call is captured. | _ / 2 |
| Model independence | Agent logic is hardcoded to a single model provider. Switching is a refactor. | You can switch models, but it requires manual configuration and re-testing. | Model-agnostic logic. You can swap providers or route based on cost/latency. | _ / 2 |
| Robust deployments | Every behavioral change requires a full application code deploy. | Some config is externalized, but updates still pass through a slow pipeline. | Behavior updates independently. Domain experts can tune the “brain” safely. | _ / 2 |
Total: __ / 12
How to read your score
The score is a measurement of your system’s structural integrity. It tells you how much luck you are currently relying on to keep your users happy.
10–12: Production-ready
You have built a professional system. You have addressed the properties that matter, and your team can ship, debug, and iterate with confidence. At this level, your focus should shift to optimizing the triangle of cost, latency, and quality.
8–9: The danger zone
You are close, but you have specific vulnerabilities. You can likely run in production today, but a single silent failure in one of your gap areas will cost more in reputational damage than the time it would take to fix it proactively.
5–7: Prototype debt
You are carrying significant technical debt. This system is fine for an internal demo or a limited beta, but it will likely surface critical issues under load. You are currently in the “Move Fast and Break Things” phase, but you are mostly breaking things.
Below 5: The happy-path trap
You have built something that works in a controlled environment. That is a great start, but there is a chasm between a demo and a product. Use this scorecard as your roadmap for what to build next.
In the early days of any technology, builders tend to start with raw code. It is often the only lever available. As the field matures, abstractions emerge. These abstractions, ideally, shift the burden of complexity and best practices from the engineer to the system.
In this section we show three distinct paths to building the same agent. To compare them fairly, we will use a single, concrete example: a product listing classifier.
The task is straightforward. The agent’s job is to take a raw product listing and return a structured classification. It must identify the category, the subcategory, and any relevant content flags like safety warnings or age ratings.
Before we get into implementation, we’ll need to cover the building blocks that every agent requires. These components (instructions, loops, multi-agent coordination, tools, knowledge, and guardrails) are universal. Understanding them first will make the approach-specific sections that follow much more concrete.
Once we’ve done that, we’ll run through three different approaches to building agents:
- Code-driven (imperative) In this approach, you write the orchestration logic yourself. You are responsible for the Python or TypeScript that handles the prompt construction, the API calls, the retry logic, and the state management. This is the path of maximum control but also maximum manual labor. You are responsible for every line of the implementation.
- Visual workflow (graph-based) This approach moves the logic to a canvas. You compose nodes and edges to define the flow of data. You can see the path from input to output. This makes the logic easier to audit visually, but it can become unwieldy as the number of nodes or edge cases grow.
- Fully managed (declarative) In this approach, you write a structured specification of the desired behavior, and a managed-agent platform runs the agent and the production stack around it. You describe the rules, schemas, and goals in a single document. The platform handles orchestration, observability, model routing, deployment, and the lifecycle of the agent itself.

The building blocks of an agent
Every agent, regardless of how it’s built, is assembled from a combination of the same fundamental pieces: instructions, a reasoning loop, tools, and guardrails. This section walks through each of those fundamental pieces.
Instructions: write prompts like you’re onboarding a new hire
Whether you write your instructions as a Python string, paste them into a node configuration, or declare them in a spec, the principles are the same. The instruction set is the single most important factor in most agents’ reliability.
Think of it as writing an SOP for a new employee on their first day. You wouldn’t hand a new hire a one-sentence description and expect them to handle every edge case correctly. You’d give them numbered steps, decision criteria, examples of tricky situations, and clear escalation paths.
The system prompt in a prototype is often a single sentence. This works for a demo, but it collapses under the weight of real-world complexity.
In a production environment, your prompts should mirror your company’s standard operating procedures, decision trees, or runbooks. If a human expert already has a manual for this task, that manual is your best starting point.
Here’s the difference between a prototype prompt and a production prompt for the same classifier:
Prototype:
Classify a product listing. Return the category, subcategory,
whether it's restricted, your confidence score (0-1), and any content flags.Production:
You are a product classifier for an e-commerce marketplace.
## Your task
Classify incoming product listings into categories and check for policy violations.
## Steps
1. Read the product title and description.
2. If a SKU is present, call lookup_product_history to check for prior classifications.
If a prior classification exists with confidence > 0.9, return it unchanged unless the description has materially changed.
3. Determine the primary category from: electronics, clothing, home, sporting, other.
4. Determine the most specific subcategory you can (e.g., "wireless headphones" not just "audio").
5. Check for policy violations:
- Weapons or weapon accessories: RESTRICTED
- Counterfeit goods (mentions "replica", "inspired by", or brand names with
suspiciously low prices): RESTRICTED
- Prohibited substances: RESTRICTED
- Health claims without disclaimer: FLAG but not restricted
6. Set confidence score:
- 0.9-1.0: Clear category, unambiguous description
- 0.7-0.89: Likely correct but description is vague or could fit multiple categories
- Below 0.7: Uncertain. Call flag_for_human_review with the reason for uncertainty.
7. If is_restricted is true, always also call flag_for_human_review with urgency "high".
## Edge cases
- Vintage or collectible items: Classify by the item's original category, not "other".
A vintage Sony Walkman is electronics, not collectibles.
- Bundles: Classify by the primary item in the bundle.
- Handmade items: Use the category of comparable manufactured goods.
- If the description is in a language other than English, do your best to classify it and add a flag: "non_english_listing".The production prompt succeeds because it breaks the task into discrete, numbered steps. It eliminates ambiguity by defining specific thresholds for tool usage and confidence scoring.
By spelling out edge cases, you prevent the model from having to guess when it encounters, say, a vintage item or a product bundle. This level of detail may feel like overkill during the initial build, but it saves significant time during the debugging phase.
A few patterns that consistently improve prompt quality:
Numbered steps over prose. Models follow numbered instructions more reliably than paragraph-form descriptions. Each step becomes a checkpoint the model can work through sequentially.
Explicit thresholds. “Flag low-confidence results” is vague. “Call flag_for_human_review when confidence is below 0.7” is actionable. Wherever you can replace a judgment call with a number, lean toward doing it.
Negative examples for edge cases. Telling the model what not to do is sometimes more effective than telling it what to do. “A vintage Sony Walkman is electronics, not collectibles” prevents a common misclassification before it happens.
Escalation paths. Every production prompt should include a “when in doubt” instruction. If the model can’t confidently complete the task, it should have a clear fallback: flag for review, ask for clarification, or return a lower-confidence result with an explanation.
The agent loop
At the heart of every agent is a cycle: observe, reason, act, repeat.
The agent receives input and a goal. It reasons about what to do next. If it decides to use a tool, it calls that tool, observes the result, and feeds that result back into its reasoning. This cycle continues until the agent has enough information to produce a final answer, determine that its task is accomplished, or a safety boundary stops it.

Three things matter in every agent loop implementation:
Iteration limits are financial and safety guardrails. Without a cap on iterations, an agent that encounters an ambiguous result or a circular tool dependency can enter an infinite loop. Every iteration burns tokens and increases your bill without producing a result. Tune the limit based on the task: a document classifier rarely needs more than three turns. A research agent that’s calling multiple APIs might need ten.
Context history is how the agent maintains state. Each time a tool is called or a step completes, the result gets added to the agent's working context. This accumulating state is what lets the agent remember what it's already tried and adjust its strategy if helpful. But there's a catch: if the loop runs too long, the context window fills up, or the model gets distracted by irrelevant earlier results. Managing context growth is a real engineering concern in any long-running loop.
Start with a single agent. It’s tempting to jump to multi-agent architectures early. But for most production workloads, a single-agent loop is more than sufficient. Multi-agent systems introduce complexity in state management and hand-offs. You should only move to a multi-agent setup when you have reached a specific complexity ceiling that a single loop cannot resolve.
Multi-agent patterns
A single-agent loop handles most production tasks well. But it has a ceiling: context dilution. This happens when the volume of tools, instructions, history, and edge cases exceeds the model’s ability to maintain focus. You’ll see it as degraded tool-selection accuracy, weaker reasoning, or hallucinations that weren’t there before.
When you hit that ceiling, you split into multiple agents, each with a narrower scope. Two patterns dominate.
The manager pattern. A central coordinator agent analyzes the incoming request and delegates it to a specialist. Each specialist has its own focused set of tools and instructions. A billing specialist only sees billing tools. A compliance specialist only sees compliance instructions. By reducing the state space each agent manages, you get more reliable behavior from the underlying model. This pattern works well for broad systems like enterprise support platforms where the request type determines which domain expertise is needed.
The handoff pattern (pipeline). Work flows in a linear sequence between agents with distinct responsibilities. For instance, Agent A might complete extraction and then pass the result to Agent B for validation, which then passes it to Agent C for final classification. Each agent has a single job and a narrow context. This is the right choice for predictable workflows where the steps are known in advance and don’t change based on content.
When to stay single-agent vs. go multi-agent: If your single agent handles its tools accurately and produces consistent results, don’t split it. If you’re seeing it confuse which tool to call, or if it starts ignoring instructions that it followed reliably when the context was smaller, those are empirical signals that you’ve hit the dilution threshold. The right time to add a second agent is when you have data showing the first one can’t keep up.
Every additional agent introduces latency and new failure boundaries. If the coordinator in a manager pattern delegates incorrectly, the entire request is lost. Keep the architecture as simple as the task allows.
Tools
Tools are how agents interact with the outside world. An agent reads a tool description, decides whether to call it, and passes structured parameters. The tool executes and returns results the agent can reason about.
Most production agents eventually need to reach outside their context: look something up, write a result somewhere, notify someone, or trigger a downstream process.
There’s a tendency to treat tools as an afterthought: get the prompt right, then bolt on some API calls. That’s backwards. Tool design shapes agent behavior as much as your instructions do. The model decides what to do based on two things: what you told it in the system prompt (or spec), and what tools are available. If your tools are poorly described, poorly scoped, or poorly structured, the agent will make bad decisions regardless of how good your prompt is.
Tools fall into three categories with different risk profiles. Data tools are read-only operations (database queries, API lookups, vector searches) that give the agent context it doesn’t have. Action tools are state-changing operations (sending emails, updating records, triggering deployments) that affect real systems. Orchestration tools hand off sub-tasks to specialized agents or trigger background workflows. Your guardrail strategy should match the risk: action tools that can send emails or update records need more protection than a read-only database lookup.
How many tools is too many?
This is changing constantly, but in our experience most models start to struggle with tool selection somewhere around 15-20 tools.
If you need more than 15 tools, that’s usually a signal that you need to split your agent into multiple specialized agents (see the multi-agent patterns above). An agent that handles billing with five focused tools will outperform one that handles everything with thirty.
A useful exercise: for each tool, ask whether you’d be comfortable removing it entirely. If the agent’s core task still works without a tool, that tool might belong in a different agent or a separate workflow.
Tool design principles
Good tool design comes down to three things:
Clear descriptions that tell the model when to use the tool, not just what it does. Write your tool descriptions as if you’re explaining to a new teammate which situations call for which tool. Include the conditions under which the tool should be used, and just as importantly, when it shouldn’t. “Do NOT use this for bulk operations” is the kind of negative instruction that can prevent expensive mistakes.
Typed parameters with constraints. Every parameter should have a type, a description, and validation rules. If a parameter expects a date, specify the format (ISO 8601, not “a date string”). If a parameter must be one of a fixed set of values, use an enum. The more specific your parameter definitions, the fewer malformed tool calls you’ll debug.
This applies to return values too. Your tool should return structured data the model can reason about, including in error cases. A tool that returns {"error": "Rate limit exceeded, retry after 30 seconds"} gives the model something to work with. A tool that throws an unhandled exception gives the model nothing.
Scope each tool to one job. A tool called manage_user that can create, update, delete, and list users is four tools pretending to be one. The model has to figure out which operation you mean from context, and it’ll guess wrong often enough to cause problems.
Scoping tool permissions
Not every tool should have the same level of trust. A read-only database lookup is low risk. A tool that sends an email to a customer is medium risk. A tool that deletes records or processes refunds is high risk.
Build your permission model around this distinction:
Read-only tools can generally run without additional guardrails. If the worst case is returning incorrect data, the model will usually catch it and try again.
Write tools should validate their inputs before executing. Check that the target exists, that the values are within expected ranges, and that the operation makes sense in context. Log every call.
Destructive or irreversible tools should require human-in-the-loop confirmation. Your agent should never be one confused inference away from deleting production data. If an action can’t be undone, make the agent prove it should happen before it does.
A common mistake is giving an agent tools it doesn’t need “just in case.” Every tool you add is a tool the model might misuse. If your product classification agent doesn’t need to send emails, don’t give it an email tool. The attack surface of your agent is the union of all its tools. Keep it as small as your use case allows.
Knowledge and RAG
Not every agent needs retrieval-augmented generation. The decision comes down to scope and stability.
Use instructions when your agent’s scope is narrow and the relevant context is stable. A product classifier that needs to know ten categories, a set of policy rules, and some edge cases can fit all of that in a well-written prompt. Adding a retrieval layer here adds latency, chunking complexity, and a new failure surface without meaningful benefit.
Use RAG when the domain knowledge exceeds what fits in a prompt, changes frequently, or spans many documents. If your agent needs to reference a 200-page compliance manual, or if the policies it enforces get updated weekly, you can’t keep that in the instructions alone. RAG lets the agent pull in only the context it needs for a given request.
The common mistake is reaching for RAG too early. Teams add vector databases and embedding pipelines because it feels like the “production” thing to do, and then spend weeks debugging retrieval quality issues that wouldn’t exist if they’d just put the relevant context in the prompt. Start with instructions. Add RAG when you hit the limits: the prompt is too long, the context changes too often, or the agent needs to search across a corpus that’s too large to include directly.
When you do implement RAG, the quality of your retrieval matters more than the quality of your model. Bad retrieval with a great model produces worse results than good retrieval with a decent model. Invest in chunking strategy, embedding quality, and relevance scoring before you upgrade the LLM.
If you’re building RAG yourself, that means standing up embedding pipelines, vector databases, and retrieval logic. Third-party platforms can simplify this significantly. If you go the managed-platform route, Logic includes a knowledge library that lets you attach documents and data sources to agents without building the retrieval infrastructure yourself.
Guardrails and safety
Guardrails aren’t optional for production agents. A chatbot that hallucinates gives you a wrong answer, but an agent that hallucinates might send a real email, delete real data, or charge a real credit card.
Effective guardrails operate at three interception points: before the model reasons, after it responds, and around each tool it can call.
Input guardrails
Filter before the agent reasons about a request. Three layers are common:
Relevance classifiers reject off-topic inputs before they consume LLM tokens. If your agent handles refund requests, it shouldn’t process questions about the weather. A lightweight classifier (or even keyword rules) can handle this cheaply.
Prompt injection detection catches attempts to override your agent’s instructions through user input. This is an active area of research with no perfect solution, but layered defenses (input scanning, instruction hierarchy, output monitoring) reduce the attack surface significantly.
PII filtering strips or masks sensitive data before it reaches the model. If your agent doesn’t need social security numbers to do its job, don’t let them into its input.
Beyond these, standard structural validation applies: check that required fields are present, that values are within expected ranges, and that the input isn’t suspiciously long or malformed. This is the same kind of input validation you’d do for any API endpoint.
Output guardrails
Schema enforcement (via Pydantic, JSON Schema, or platform-level validation) ensures the output matches a defined type. But valid structure doesn’t guarantee correct content. A model can return a perfectly formatted JSON object that’s factually or logically wrong.
Hard-coding semantic validation checks for every possible error is a losing battle. The professional solution is the critic pattern: use a secondary agent (often a smaller, cheaper model) to review the primary agent’s output against a set of quality criteria. The critic checks for logical consistency, flags suspicious patterns, and can reject outputs that pass structural validation but fail semantic review.
For example, a critic for a product classifier might check: Is the confidence score high but the category set to “Other”? Is an item marked as restricted but the flags don’t explain why? Is the subcategory a logical subset of the primary category? These are checks that are hard to express as code rules but easy to express as natural language criteria for a second model.
The critic can also serve as a natural language audit trail, which is valuable in regulated domains.
Tool-level guardrails
Tool-level safety enforces the principle of least privilege. It ensures the agent cannot execute unauthorized actions, regardless of the instructions it received. This is where you enforce rate limits, approval requirements for destructive actions, and scope restrictions.
A product classifier shouldn’t be able to delete products, even if someone manages to inject that instruction. The allowlist of available tools is your hard boundary. Anything not on the list is blocked regardless of how convincingly the model argues for it.
When to escalate to humans
Your agent will get things wrong, especially early on. Human intervention gives you a way to catch those failures and improve the agent’s performance without burning user trust. The goal is a graceful handoff: when the agent can’t complete a task, it transfers control to a human rather than guessing its way into a worse outcome.
What that handoff looks like depends on your use case. A customer service agent escalates to a human support rep. A coding agent surfaces the problem and hands control back to the developer. A document processing agent flags the item for manual review. The shape is different, but the principle is the same: the agent should know its own limits and act on them.
Two triggers should always warrant escalation:
Exceeding failure thresholds. Set limits on retries and repeated failures. If the agent can’t understand a customer’s intent after three attempts, or if it keeps hitting errors on a particular task, escalate. Define these limits before you deploy, not after a user has already sat through five failed attempts.
High-risk actions. Actions that are sensitive, irreversible, or carry real financial consequences should require human approval until you’ve built confidence in the agent’s reliability. Canceling orders, issuing large refunds, modifying account permissions: these shouldn’t be one confused inference away from happening. As your agent proves itself over time, you can selectively loosen the reins.
Build the escalation path before you need it. An agent that fails silently is worse than one that asks for help.
The building blocks above are universal. Every agent needs some combination of instructions, a loop, tools, and guardrails regardless of how you build it. What changes is how you implement them. The next three sections walk through the same product classifier built three different ways: writing the code yourself, assembling it in a visual workflow tool, and defining it as a spec. Each approach makes different trade-offs around control, speed, and maintenance burden.
A. Code-driven (imperative)
In the imperative approach, you as developer are responsible for the entire orchestration lifecycle. This includes managing state, handling model input and output, and implementing the necessary logic for error recovery.
Most engineers begin with this method because it maps directly to standard software development patterns. You use familiar languages like Python or TypeScript and maintain granular control over the execution flow.
The code-driven path splits into two practical starting points. DIY on raw API calls is where most teams begin: you call the OpenAI, Anthropic, or Google API directly, parse the response, and build everything else yourself. It teaches you the underlying primitives, but you take on the cost of building retries, validation, logging, and testing on your own. Frameworks sit one layer up. They provide opinionated abstractions for prompts, tool calling, and state management. Both are flavors of imperative orchestration: you write the orchestration logic and you ship it as application code.
The example below uses raw API calls so the contract stays visible. Frameworks are covered later in this section.
The following implementation demonstrates a basic product classifier using the OpenAI SDK and Pydantic for schema enforcement.
import logging
from enum import Enum
from typing import Optional
from openai import OpenAI
from pydantic import BaseModel, Field
SYSTEM_PROMPT = (
"Classify this product listing. Return the category, subcategory, "
"if it's restricted (boolean), confidence score (0-1), and any content flags."
)
class Category(str, Enum):
ELECTRONICS = "electronics"
CLOTHING = "clothing"
HOME = "home"
SPORTING = "sporting"
OTHER = "other"
class Classification(BaseModel):
category: Category
subcategory: str = Field(description="The specific niche within the category")
is_restricted: bool
confidence: float = Field(ge=0, le=1)
flags: list[str]
def classify_product(
title: str,
description: str,
max_retries: int = 3,
model = 'gpt-5.4',
client: OpenAI = OpenAI(), # For dependency injection
) -> Optional[Classification]:
"""
Orchestrates the classification of a product listing with retry logic.
"""
for attempt in range(max_retries):
try:
response = client.beta.chat.completions.parse(
model=model,
response_format=Classification,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": f"Title:{title}\\\\\nDescription:{description}"}
],
)
return response.choices[0].message.parsed
except Exception as err:
logging.error(f"Attempt{attempt + 1} failed:{err}")
if attempt == max_retries - 1:
# In a real system, you would emit a metric here
raise err
return NoneThis implementation is functional and concise. In roughly 30 lines, it addresses two of our six properties: reliability (via Pydantic contracts) and basic resilience (via a retry loop).
However, this is a solitary component, not a production system. To bridge the gap to a production-ready agent, several non-trivial engineering challenges remain. When you hardcode orchestration logic in this manner, you assume the burden of building and maintaining the infrastructure for observability, versioning, and evaluation yourself.
Model selection: start with capability
In the code example above, we specified gpt-5.4. However, at the prototyping stage, the specific provider is secondary to the logic of the agent. The priority is to establish a baseline of correct behavior using a frontier-class model.
A common pitfall is to spend cycles benchmarking models before your agent is even functional. While optimization is a valid engineering goal, you cannot effectively optimize a system without data. Benchmarking without a working agent is a speculative exercise rather than an empirical one.
The development sequence
The most efficient path to production follows a specific order of operations:
- Establish the baseline: Build the agent using a high-capability model to ensure your instructions and schemas are sound.
- Define the evals: Create a set of test cases based on real or synthetic data.
- Optimize for the triangle: Once you have a working baseline, run your evals against smaller, faster, or cheaper models.
Tiered routing
As you move toward production, it will usually make sense to adopt a tiered routing pattern. In this architecture, a lightweight classifier evaluates the complexity of an incoming request. Simple tasks are routed to a fast, cost-effective model, while high-complexity reasoning is reserved for more capable frontier models.
This approach allows you to maximize quality while minimizing latency and cost. However, this is an optimization for later. For now, the goal is functional correctness.
Design for change
Even in the earliest prototype, do not scatter model names throughout your codebase. Centralize your model selection in a configuration file or a global constant. This minor architectural discipline ensures that when it is time to swap models or implement routing logic, you are not performing a global find-and-replace across your entire repository.
Instructions
The production prompt from the building blocks section gets implemented as a Python string assigned to a constant. Here’s the practical difference in the code-driven approach: the prototype prompt and the production prompt are both just strings, but the production version does substantially more work.
The prototype prompt we started with:
SYSTEM_PROMPT = (
"Classify this product listing. Return the category, subcategory, "
"if it's restricted (boolean), confidence score (0-1), and any content flags."
)Gets replaced by the full production prompt (see the building blocks section for the complete text). In a code-driven system, you’d typically store this in a constants file or load it from a configuration system so it’s easy to find, update, and version.
Tools
The building blocks section above covered why tool design matters, how to categorize tools, and how to scope permissions. Here’s what that looks like in practice.
A tool is defined by its name, a set of parameters, and a description. This description is not just for documentation. It’s also the primary signal the agent uses to decide when to call it.
Here are two tool definitions for our product classifier.
Tool: lookup_product_history
Description: "Look up previous classifications for a product by SKU.
Use this when the product has been classified before and you want
to check for consistency."
Parameters:
sku (string, required): The product SKU to look up
Returns: { found, previous_category, last_classified } or { error }
Tool: flag_for_human_review
Description: "Flag a product for manual review by the compliance team.
Use this when confidence is below 0.7 or the product might violate
marketplace policies."
Parameters:
sku (string, required)
reason (string, required): Why this product needs human review
urgency (string, one of: "low", "medium", "high")
Returns: { success, ticket_id } or { error }
Each tool implementation handles its own errors and returns structured
results the model can reason about, including in failure cases.Two specific details make these definitions effective in a production setting.
First, the descriptions include clear heuristics. Phrases like “Use this when confidence is below 0.7” provide the model with a quantitative trigger. Without these instructions, a model may hesitate to use a tool or use it at inappropriate times.
Second, the return values are structured to handle failure. If a database query fails, the tool should return a structured error object rather than throwing an exception that crashes the execution loop. When the model receives an error object, it can reason about the failure. It might choose to retry, attempt an alternative strategy, or escalate the issue to a human.
If your tools fail silently, the agent may either stall or attempt to hallucinate a successful result to satisfy the prompt.
The agent loop
The observe-reason-act cycle from the building blocks section gets implemented as a for loop with tool dispatch:
import json
def run_agent(task: str, max_iterations: int = 10) -> dict:
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": task}
]
for i in range(max_iterations):
# The model decides the next step based on the conversation history
response = client.chat.completions.create(
model=MODEL,
messages=messages,
tools=TOOLS,
)
msg = response.choices[0].message
# Execution phase: if the model requests a tool, we run it
if msg.tool_calls:
messages.append(msg)
for tool_call in msg.tool_calls:
fn_name = tool_call.function.name
fn_args = json.loads(tool_call.function.arguments)
# Observation phase: execute the tool and capture the result
result = execute_tool(fn_name, fn_args)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(result)
})
# Continue the loop to let the model process the new information
continue
# Exit phase: if no tools are called, the task is complete
return {
"status": "complete",
"response": msg.content,
"iterations": i + 1
}
return {
"status": "max_iterations_reached",
"iterations": max_iterations
}
def execute_tool(name: str, args: dict) -> dict:
tool_map = {
"lookup_product_history": lookup_product_history,
"flag_for_human_review": flag_for_human_review,
}
fn = tool_map.get(name)
if not fn:
return {"error": f"Unknown tool:{name}"}
try:
return fn(**args)
except Exception as e:
return {"error": str(e)}The max_iterations cap, context history management, and single-agent-first principle discussed in the building blocks section are all visible here. The messages list grows with each tool call, and the loop terminates either when the model stops requesting tools or when the iteration limit is reached.
Multi-agent orchestration
When a single-agent loop hits the context dilution threshold discussed earlier, the manager pattern looks like this in code:
from pydantic import BaseModel
from typing import Literal
class DelegationPlan(BaseModel):
"""
Schema for the manager to decide which agent to invoke
and what specific instructions to give them.
"""
specialist: Literal["classifier", "researcher", "reviewer"]
subtask: str
def manager_agent(task: str) -> dict:
# The manager decides which specialist to invoke
plan = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": (
"You are a coordinator. Given a task, decide which specialist "
"to delegate to: 'classifier', 'researcher', or 'reviewer'. "
"Return the specialist name and the task to hand off."
)},
{"role": "user", "content": task}
],
response_format=DelegationPlan, # Pydantic model with specialist + subtask
)
delegation = plan.choices[0].message.parsed
return run_specialist(delegation.specialist, delegation.subtask)By isolating domains, each specialist only manages its own tools and instructions. This reduction in state space significantly increases the reliability of the underlying model.
Guardrails
The three interception points from the building blocks section (input, output, tool-level) each get their own implementation.
Input validation:
Input validation occurs before the request is sent to the model. This layer ensures the data adheres to structural constraints and filters for known adversarial patterns, like prompt injection attempts. This is fairly standard software validation.
def validate_input(title: str, description: str) -> tuple[bool, str]:
if not title or len(title) > 500:
return False, "Title must be between 1 and 500 characters"
if not description or len(description) > 10000:
return False, "Description must be between 1 and 10000 characters"
# Basic heuristic check for prompt injection. In production, use a guardrail model
suspicious_patterns = ["ignore previous instructions", "system:", "you are now"]
for pattern in suspicious_patterns:
if pattern.lower() in description.lower():
return False, "Input contains suspicious content"
return True, "ok"Output validation with a critic:
While schema enforcement (via Pydantic) ensures the output matches a defined type, it does not guarantee semantic correctness. A model can return a perfectly formatted JSON object that is still factually or logically incorrect.
Hard-coding semantic validation checks is a losing battle. Attempting to write manual logic to determine if a product description truly matches a specific category leads to a brittle codebase that cannot scale with the nuances of real-world data.
The professional solution is to implement a model-based evaluation pattern, using a secondary agent to act as a critic.
CRITIC_PROMPT = (
"You are a quality control auditor. Review the following product classification. "
"Check for logical consistency. A classification is INVALID if: "
"1. The confidence is high ( >0.9 ) but the category is 'Other'. "
"2. The item is 'Restricted' but the flags do not explain why. "
"3. The subcategory is not a logical subset of the category."
)
def validate_output_with_critic(listing: str, result: Classification) -> tuple[bool, str]:
# We use a smaller, faster model for the critic role to maintain efficiency
response = client.beta.chat.completions.parse(
model="gpt-5-mini",
messages=[
{"role": "system", "content": CRITIC_PROMPT},
{"role": "user", "content": f"Listing:{listing}\\\\\nResult:{result.json()}"}
],
response_format=ValidationResult # Schema: is_valid: bool, reason: str
)
audit = response.choices[0].message.parsed
return audit.is_valid, audit.reasonUsing a smaller model for the critic keeps cost and latency low. The critic can also double as a natural language audit trail, which is valuable in regulated domains.
Tool-level safety:
Tool-level safety enforces the principle of least privilege. It ensures the agent cannot execute unauthorized actions, regardless of the instructions received from the model or an external user.
This is where you enforce things like rate limits, approval requirements for destructive actions, and scope restrictions. A product classifier shouldn’t be able to delete products, even if someone manages to inject that instruction.
ALLOWED_TOOLS = {"lookup_product_history", "flag_for_human_review"}
def execute_tool_safe(name: str, args: dict) -> dict:
if name not in ALLOWED_TOOLS:
return {"error": f"Tool '{name}' is not permitted for this agent"}
# Additional per-tool checks
if name == "flag_for_human_review":
if args.get("urgency") == "high":
log.warning(f"High-urgency review flag:{args.get('reason')}")
return execute_tool(name, args)In an imperative system, these guardrails are mandatory. Without them, the agent is vulnerable to prompt injection, where a clever input can override your system instructions. By implementing these checks in code, you move the security boundary from the probabilistic world of the LLM to the deterministic world of your application logic.
A product classifier, for instance, should have no mechanical path to deleting records or accessing unauthorized databases, even if the model is explicitly instructed to do so by a malicious input.
The production gap
At this stage, you have a functional agent. It manages model selection, tool execution, and validation logic. However, there is a significant distance between a functional script and a production-grade service. When measured against the six properties of a production agent, several structural deficits remain.
- Versioning and rollbacks: Because your prompt is a hardcoded string, it is tied to the lifecycle of your application code. You cannot roll back a behavioral change without reverting a git commit and redeploying the entire service. Comparing the performance of two different prompt versions requires building a custom harness.
- Systematic evaluation: A script that works on hand-tested examples is not verified for production. A reliable pipeline requires running hundreds of test cases against specific prompt versions to catch regressions. Without this, you are effectively testing in production.
- Traceability and logging: When a failure occurs, you need to see the full execution trace. This includes the specific system prompt that was active, the tool call sequence, and the intermediate reasoning steps. Capturing this data requires building structured logging for every decision point in the loop.
- Architectural flexibility: Hardcoding a single model provider creates a dependency that is difficult to break. Implementing fallbacks, dynamic routing, or cost-based model swapping becomes a separate, complex workstream rather than a configuration change.
- Deployment velocity: If the people who understand the domain, like the product managers or subject matter experts, want to iterate on the agent behavior, they are currently blocked. Every minor adjustment requires an engineering ticket.
The code required to build the infrastructure around an agent (testing, versioning, observability, and deployment) is often orders of magnitude more complex than the agent itself.
Orchestration frameworks
Frameworks aim to standardize the boilerplate of agent development. They provide abstractions for model providers, tool calling conventions, and state management. The value proposition is that you can focus on the business logic while the framework handles the underlying plumbing.
Each framework takes a different design approach:
- LangChain: The largest collection of integrations and the most extensive set of pre-built connectors. It offers high-level abstractions for almost every part of the LLM lifecycle. It also introduces significant complexity through its multi-layered architecture.
- LlamaIndex: Optimized for data-intensive tasks. It provides sophisticated primitives for indexing, retrieval, and RAG (Retrieval-Augmented Generation).
- CrewAI: Specifically designed for multi-agent coordination. It simplifies the process of defining specialists and managing their interactions.
- PydanticAI: A more recent, type-safe approach. It prioritizes developer experience by staying closer to native Python patterns and direct API calls.
- Haystack: An enterprise-oriented framework focused on production-grade RAG and search pipelines. It provides retrievers, document stores, and modular pipeline components, with a longer history in NLP than the newer agent-first frameworks.
Abstractions always have trade-offs
While frameworks accelerate the initial build, they introduce a layer of indirection that can complicate production operations. When an agent fails, you are often forced to debug through several layers of third-party code.
This leads to a common failure mode: the “framework tarpit.” Teams adopt a framework to save time, but eventually spend more time fighting the framework’s opinions and limitations than they would have spent writing the direct orchestration logic.
Frameworks tend to be most effective in two situations:
- You need specific pre-built connectors, like LlamaIndex's document loaders or database integrations.
- Your team is new to LLM APIs and benefits from the structure a framework provides.
Direct implementation is generally preferable when you need:
- Rigor: You need to understand and control every failure mode at the API level without hidden middleware.
- Simplicity: The agent’s logic is straightforward enough that a framework adds more weight than value.
- Extra flexibility: The framework’s built-in assumptions about memory or prompt formatting conflict with your specific performance or security needs.
If you’re beginning a new project and prefer to start with code, the most pragmatic path is to start with direct API calls. This ensures you understand how the components interact. If you later encounter a level of complexity that justifies a framework, you will be making that choice based on technical requirements rather than a search for a shortcut.
For many agents that follow standard patterns, the managed-platform approach discussed below often provides a faster route to both prototype and production.
When code-driven is the right call
The decision to build a code-driven agent should be based on the novelty and complexity of the task. If your requirements align with established patterns (such as extraction, classification, or standard RAG) the overhead of imperative orchestration is rarely justified. However, two specific scenarios benefit from the flexibility of code.
Integration with non-standard systems
Code-driven agents are essential when you require fine-grained control over interactions with proprietary or legacy systems. If your agent must navigate complex authentication flows, coordinate with non-standard protocols, or manage state across fragmented internal APIs that no platform could reasonably anticipate, manual orchestration is usually the only way to get reliability.
Novel architectures and “greenfield” experiments
If you are developing a use case that does not yet have an established design pattern, the flexibility of code is worth the infrastructure cost. Platforms excel at optimizing known workflows, but code allows you to experiment with unique reasoning loops, bespoke memory structures, or custom feedback mechanisms that have not yet been standardized.
Evaluating engineering allocation
To determine if your current approach is sustainable, audit where your team spends its time. In most professional engineering environments, effort should be directed toward refining the agent’s actual behavior and domain expertise.
If most of your resources are diverted toward building deployment pipelines, maintaining testing harnesses, or managing prompts, you are no longer building an agent; you are building an AI operations platform. Unless that platform is your core product, this is likely an inefficient allocation of engineering capital. The goal is to redirect that effort away from the infrastructure and toward the part of the system that creates competitive value: the agent’s logic.
B. Visual workflow (graph-based)
In a visual workflow, the primary abstraction is the Directed Acyclic Graph or DAG. Instead of defining logic through imperative control flow in a Python or TypeScript file, you arrange functional nodes on a canvas and draw edges to dictate the data path. Each node serves as a discrete unit of work: an API trigger, a prompt template, an LLM call, or a conditional router.
Tools like n8n, LangGraph and Zapier characterize this approach. The core value proposition is the ability to see the mental model of the system at a glance without parsing a codebase.
When we map the product listing classifier to a visual workflow, the logic becomes self-documenting. Here's what the same agent looks like built in n8n:
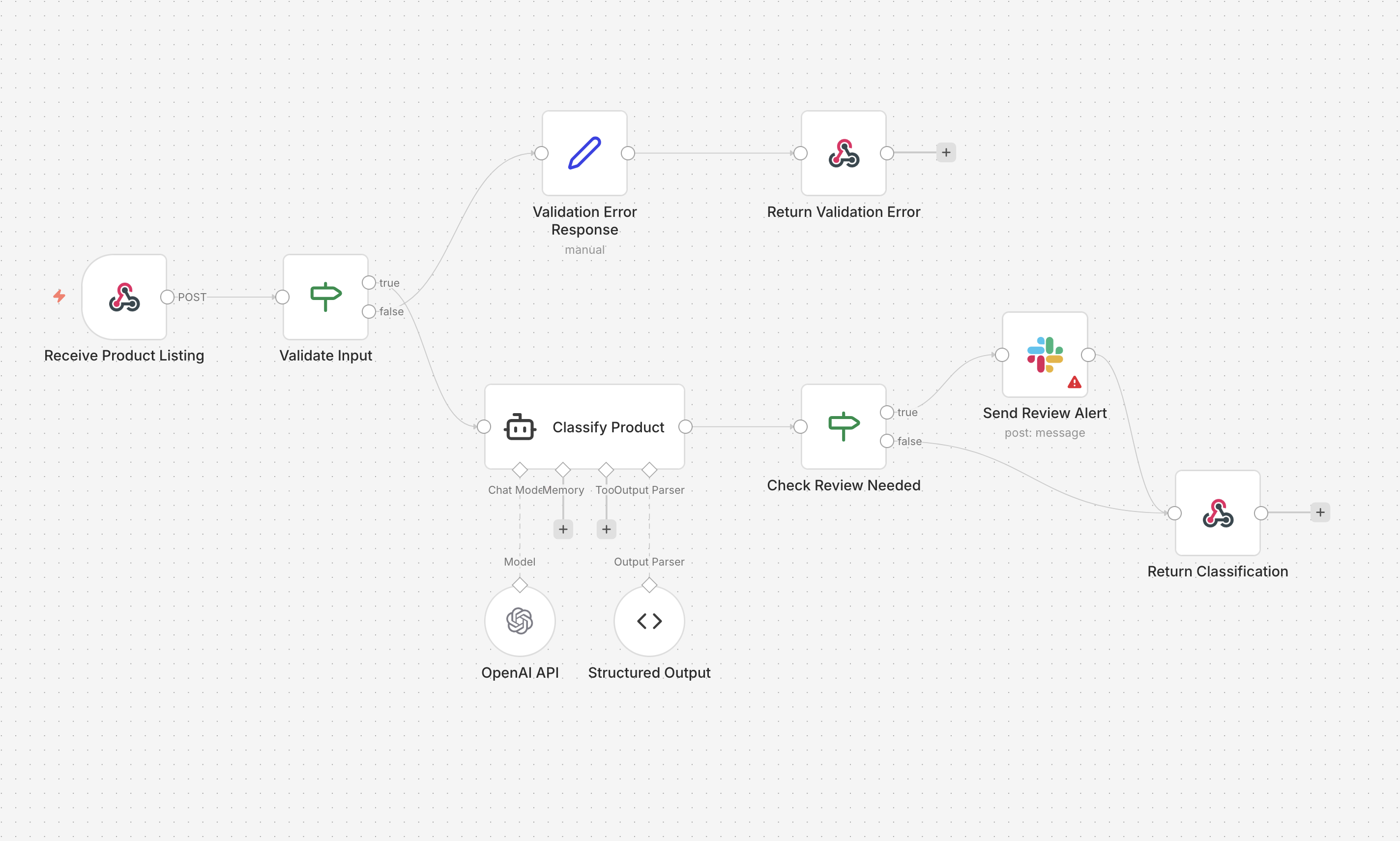
- Ingestion: A Webhook node receives the raw product listing via POST.
- Input Validation: An IF node checks that required fields are present and within expected bounds. If validation fails, the flow branches to an error response. If it passes, it continues.
- Classification: An AI Agent node, backed by OpenAI and a structured output parser, classifies the listing into a category, subcategory, confidence score, and content flags.
- Review Router: A second IF node checks whether the item needs human review (restricted item or low confidence). If it does, the flow branches to send a Slack alert before returning the result. If it doesn't, the classification is returned directly.
The whole thing is eight nodes. You can physically trace the fork where a standard listing passes through cleanly while a flagged one triggers a Slack notification on its way out. A technical Product Manager can audit this logic in seconds, making it a living spec that bridges the gap between engineering and policy teams.
That’s the real strength of visual workflow tools.
If your agent fits this shape, visual tools are a strong choice. The rest of this section covers how to build production-quality agents with them, where they excel, and where you’ll need to work around their limitations.
Model independence
Visual tools offer an advantage in per-agent model granularity. In n8n, this is managed via a connected LLM node from the AI Agent node. In Zapier, it is a model selector inside an Agent step.
You configure an LLM node by clicking into it and selecting a provider and model from a dropdown menu, along with parameters like temperature. In the product listing classifier above, a single OpenAI model handles the classification. The graph shows you that OpenAI is the provider, but the specific model version is a setting inside the node, not something you can read from the zoomed-out canvas. You'd need to click into it to know whether it's running GPT-5.4 or GPT-5-mini.
Because each AI Agent node manages its own model independently, you could split the workflow into two stages with different models: a fast, cost-effective model like Gemini 3 Flash for initial category sorting, and a high-reasoning model like GPT-5.4 or Claude Opus 4.6 for policy violation checks. The provider is visible at a glance; the exact model and its parameters are one click deeper.
The primary downside of this convenience is evaluation debt. While swapping a model takes only two clicks, visual tools rarely provide the native infrastructure to detect, say, a 4 percent drop in classification accuracy. This gap shows up in three ways:
- Misleading spot-checks: Running a few sample inputs through the canvas is not a substitute for a statistically significant test.
- Eval gap: Without an external evaluation suite, you are flying blind with every model update.
- Regression risk: A model that is better at general reasoning may perform worse on your specific edge cases for restricted items.
In a production setting, the ease of swapping models in a GUI must be balanced by a rigorous, externalized testing harness. If you cannot measure the impact of a model change across your entire golden set of data, you have traded reliability for a minor gain in developer speed.
Tools and connectors
Connectors are the primary utility of visual workflow tools. Pre-built nodes handle the boilerplate of REST APIs, Postgres queries, and webhook ingestion without requiring manual implementation of authentication or retry logic.
Zapier supports more than 8,000 integrations, while n8n offers over 500. For a product listing classifier, this would simplify the ingestion of data from sources like Shopify and the subsequent export of results to a compliance dashboard or a database.
Custom logic implementation
When you encounter logic that does not fit a pre-built connector, you must use a dedicated code node. n8n supports JavaScript and Python in these blocks, while Zapier offers a more restricted environment.
These nodes are not full-fledged execution environments. They are sandboxed script blocks with significant operational constraints:
- Execution timeouts: Most platforms enforce strict limits, often between 10 and 30 seconds. This can be a bottleneck for complex data transformations or multi-step validation logic.
- Dependency management: You are restricted to the libraries pre-installed by the platform. You cannot easily add niche packages required for specific data processing tasks.
- Lack of persistence: These environments usually lack a persistent filesystem and have limited memory, making them unsuitable for heavy data manipulation.
If your classifier requires non-standard library support or handles large payloads, you will eventually hit the ceiling of what these embedded scripts can provide. At that point, the visual clarity of the graph is undermined by the complexity hidden inside fragmented snippets of code.
Context fragmentation and instruction management
In visual tools, system prompts are encapsulated within individual LLM nodes. For a basic implementation, this is straightforward: you configure the Prompt or System Message field within a single node. The architecture is transparent and easy to audit.
As the product listing classifier grows in complexity, however, this approach introduces significant cognitive load. A production-grade agent will need to account for marketplace-specific regulations, vintage item edge cases, and distinct protocols for restricted categories. In a code-driven or managed-platform architecture, this logic resides in a centralized configuration or source file that can be read and versioned as a single unit.
In a visual workflow, these instructions inevitably become fragmented. The primary classification prompt lives in the initial LLM node. Rules for restricted items are buried in a separate node on a downstream branch. Logic for handling specific edge cases might be split between a router configuration and a specialized review node.
The discovery problem
This fragmentation complicates the process of understanding the agent’s total knowledge base. A technical lead attempting to verify the system’s compliance with new policy updates cannot perform a simple global search or read a single document. Instead, they must open every LLM node in the graph, extract the prompt text, and reconstruct the agent’s global state.
This decentralized approach to instruction management creates several operational risks:
- Inconsistent logic: A change to a policy rule might be updated in the primary classifier node but overlooked in a secondary validation node, leading to divergent behavior within the same workflow.
- Onboarding friction: New agent maintainers must perform a manual discovery process across the canvas to understand what the agent knows, rather than reviewing a centralized behavioral specification.
- Auditability: Verifying the exact context provided to the model during a specific execution requires tracing the path through multiple nodes, each with its own local instruction set, making it difficult to pinpoint where a reasoning failure originated.
While visual tools make the data path clear, they often obscure the instructional intent that governs that path.
Orchestration patterns and the complexity explosion
Orchestration is the primary function of a visual builder and the area where its structural constraints are most visible. While these tools excel at simple pipelines, they often struggle with the non-linear logic required for professional-grade agents.
Data flow
Visual tools are optimized for sequential execution. A request enters, passes through a series of discrete nodes, and exits as a processed result. The product listing classifier begins as this type of linear flow: an ingestion node followed by a classification node and a final output. This is the ideal use case for a GUI, as the visual representation is functionally identical to the mental model of the task.
Conditional branching (implemented via Switch or Path nodes) remains effective for low-complexity routing. If the classifier needs to fork logic for three broad categories, the canvas remains readable. However, as requirements grow to include a dozen specific marketplace policies, the canvas begins to experience sprawl. Tracing a specific execution path through a web of overlapping edges requires constant zooming and panning, which makes it challenging to reason about the system as a whole.
Iteration
Iteration is a fundamental friction point for directed acyclic graph (DAG) interfaces. In an imperative script, a retry loop or an iterative refinement pattern is a few lines of code.
In a visual canvas, implementing a “critic” pattern (where the agent refines its classification based on feedback) requires wiring an output back to a preceding input. This creates a visual cycle that breaks the linearity of the graph.
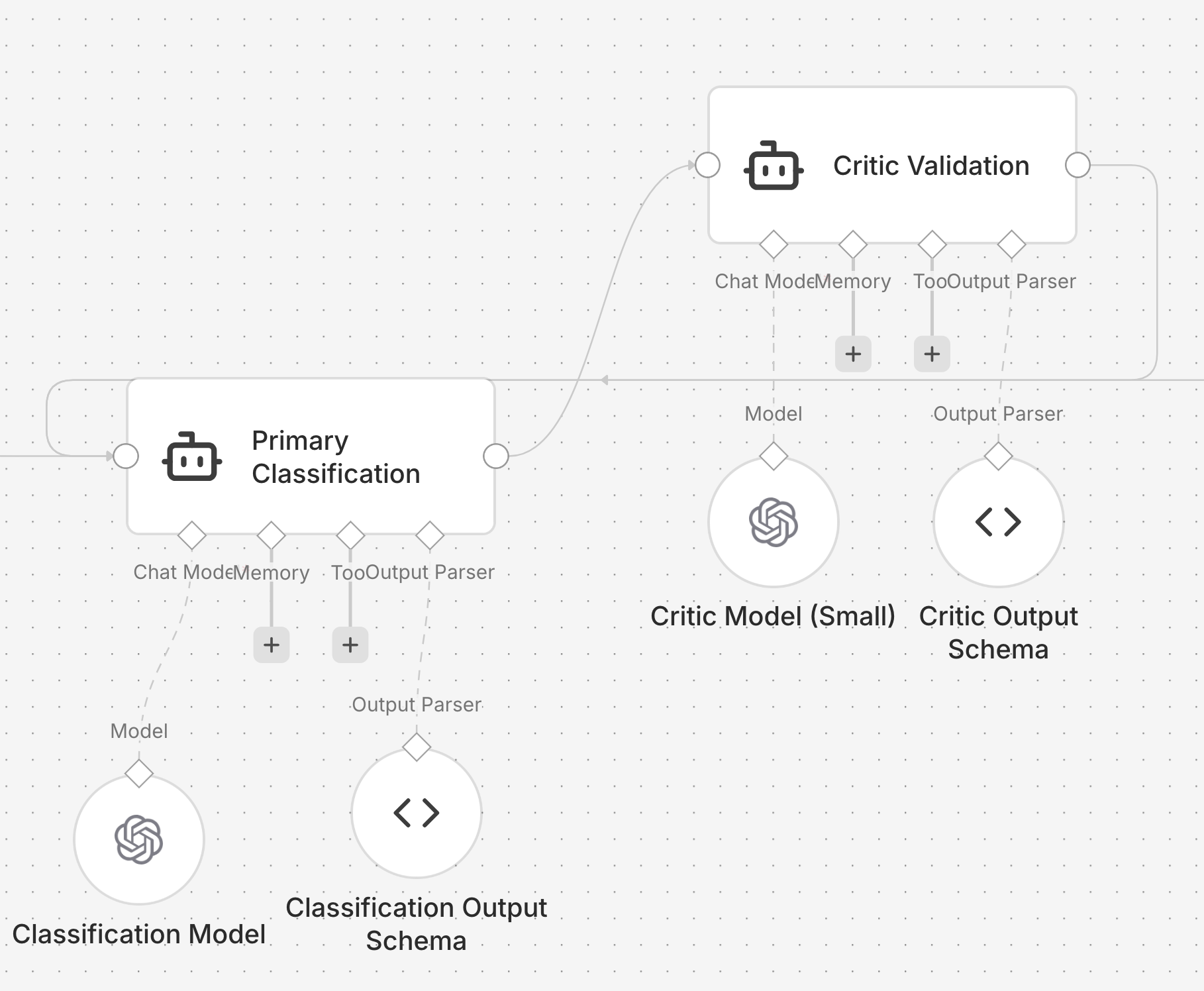
This introduces several operational challenges:
- State visibility: It is difficult to determine which iteration of a loop you are currently inspecting in a debugger.
- Termination logic: Ensuring a loop terminates correctly is often more complex in a GUI than in code, where
breakconditions are explicit and easily unit-tested. - State accumulation: Managing how data changes across multiple passes, such as appending new reasoning steps to a history, often requires manual variable management that is prone to error.
Multi-agent coordination
Multi-agent patterns in visual tools generally manifest in two ways: nested workflows (where a node triggers a sub-process) or monolithic graphs partitioned into functional zones.
The coordinator pattern, where a manager model delegates to specialists, is feasible through nested workflows. However, debugging across workflow boundaries adds a layer of complexity that doesn’t exist in a single graph. State that needs to pass between workflows must be explicitly serialized and deserialized, and errors in a sub-workflow may surface as opaque failures in the parent. The handoff pattern (where Agent A passes control to B, which might pass it back based on a specific condition) is notoriously difficult to represent. When control flow becomes circular or highly conditional, the canvas ceases to be an aid and becomes a hindrance to understanding the system’s state.
Node paralysis
Most engineering teams hit a complexity threshold around the 20 to 30-node mark. At this scale, the “visual” advantage begins to evaporate. Engineers spend a disproportionate amount of time managing node placement and edge routing rather than refining the agent’s reasoning logic.
This is not a failure of the tools themselves but an inherent limitation of visual programming for complex logic. Just as visual database query builders and CI/CD editors eventually give way to SQL and YAML as requirements scale, visual agents hit a ceiling where the canvas can no longer represent the underlying algorithmic complexity. The canvas is a viewport with finite dimensions, and human spatial reasoning cannot scale to the same depths as hierarchical, text-based logic.
Guardrails in visual tools
Visual platforms vary widely in how they handle guardrails, and the level of sophistication depends heavily on which tool you’re using.
Input validation typically takes one of two forms: a dedicated validation node at the start of the flow, or a code node that runs custom JavaScript or Python to check inputs before they reach the LLM. Most platforms don’t offer built-in prompt injection detection, so you’ll either need to roll your own in a code node or call an external API that handles it. For structural validation (checking required fields, data types, string lengths), code nodes work fine. For semantic filtering (”is this input on-topic?”), you might add a lightweight LLM node as a pre-filter, though this adds latency and cost.
Output validation follows a similar pattern. You can add a checker node after the LLM response that verifies the output against expected schemas or business rules. Implementing the critic pattern discussed in the building blocks section means adding a second LLM node that reviews the first one’s output. This is entirely possible in a visual tool, but it adds nodes, edges, and complexity to the graph. When every guardrail is a visible node, a well-guarded agent can look significantly more cluttered than an unguarded one.
Tool permissions are handled at the platform level in most visual tools. n8n and Zapier control which integrations are available and what credentials they use. But fine-grained per-tool permissions (like restricting an agent from calling a destructive operation based on context) usually require custom logic in a code node. The platforms themselves rarely offer a declarative way to say “this tool requires human approval before execution.”
Testing and evaluation
The absence of a native, automated testing framework is a significant structural gap in visual workflow development. While these platforms prioritize speed of construction, they frequently lack the mechanisms required to verify systemic reliability at scale.
Manual verification limits
Most visual tools offer a “run with sample input” feature as the primary verification mechanism. This function confirms that the workflow can execute without throwing a runtime error on a single specific input.
However, passing a manual test on one input does not indicate whether the output is semantically correct, nor does it guarantee the agent will handle the next hundred edge cases. It is a check for structural integrity, not for reasoning accuracy.
Externalized testing and evaluation
Native solutions are emerging, such as n8n’s evaluations feature, which allows teams to define datasets and measure output quality across different model versions. While this is a step toward maturity, most visual platforms still lack the assertion libraries and regression testing suites found in traditional software engineering.
To achieve production-grade reliability, architects typically externalize the testing logic:
- API-First Testing: Triggering the workflow via a webhook from a dedicated external test suite (using frameworks like Pytest or Jest).
- Shadow Deployments: Routing production traffic through a new version of the graph in parallel with the live version, comparing outputs without surfacing them to the user.
- LLM-as-a-Judge: Integrating a secondary “evaluator” graph that automatically scores the outputs of the primary classification agent against a golden dataset.
If you are building an agent that requires high precision, the time saved by using a visual builder will likely be reabsorbed by the effort required to build this externalized testing infrastructure. In a professional deployment, you are not simply testing the nodes; you are testing the probabilistic distribution of the agent’s behavior.
Version control and deployment
Version control is another area where visual tools diverge from standard engineering practices. In a code-driven system, every change is captured in a git commit, providing a clear history of what was changed, by whom, and why.
In visual tools, versioning is often managed by the platform itself with detailed, node-level diffs almost impossible to track.
Git integration and synchronization
Platforms like n8n and LangGraph offer ways to export workflows as JSON files, which can then be checked into a git repository. This allows for some level of version control, but it introduces a friction-filled workflow:
- Modify the graph in the UI.
- Export the JSON.
- Commit and push the JSON to Git.
- Import the JSON into a different environment (e.g., Staging to Production).
This manual synchronization is prone to error and makes “diffing” changes (seeing exactly what changed between two versions) difficult. A change to a single edge or a prompt hidden inside a single node might result in a massive JSON diff.
Deployment and rollbacks
Deploying a visual agent often doesn’t include the safety of a traditional CI/CD pipeline. In many cases, “deploying” simply means hitting the Save or Publish button on the canvas.
While this speed is attractive, it lacks the guardrails of automated testing and staging environments. If a change to a prompt in the classification node causes a regression, rolling back may require manually reverting the node’s configuration or importing an older JSON export. Without a sophisticated deployment strategy, visual workflows can easily become a “edit in production” environment, which is a high-risk pattern for any mission-critical agent.
The production gap
When we evaluate the visual workflow approach against the six properties of production-grade agents, a clear profile emerges. While these tools offer high velocity for initial builds, they often lack the structural rigor required for mission-critical systems.
- Reliable responses (partial): Most visual tools allow for output parsers or validation nodes, but enforcement is inconsistent. You can verify that a JSON object is syntactically correct, but validating that every required field is present and correctly typed often requires custom code nodes.
- Testability (weak): This remains the most significant hurdle. Native testing is usually limited to single-input manual runs. For high-confidence deployments, you will likely need to build an external test harness that triggers the workflow via API.
- Version control (basic): While platform-level versioning exists, it lacks the utility of Git. Diffing changes between two versions of a 30-node graph is difficult, and rolling back a single logic change without affecting the entire workflow is often impossible.
- Observability (solid): Visual execution traces are a major strength. Being able to see exactly which path a request took and what each node produced is invaluable for debugging. However, deep analysis or long-term trend monitoring usually requires exporting these logs to an external observability stack.
- Model independence (manual): Model selection is node-level. Switching from GPT-5.4 to Claude Opus 4.6 requires manual updates to individual nodes. There is rarely a mechanism for automatic fallback or dynamic routing based on latency or cost.
- Robust deployments (strong velocity): This is the primary advantage. Behavioral changes (such as updating a prompt or adding a validation step) can be live in seconds. This speed is ideal for internal tools but carries significant risk for customer-facing systems without a staging environment.
On our production readiness scorecard, a typical visual workflow setup scores between 4 and 7. The final score depends heavily on how much external infrastructure you build to compensate for the tool’s inherent limitations in testing and versioning.
When visual workflows are the correct choice
Choosing a visual tool is a strategic decision based on the nature of the task and the team’s composition. It is not necessarily a compromise if your requirements align with the tool’s strengths.
Linear and low-complexity logic
If your agent follows a predictable path with a limited number of decision points, the visual representation is genuinely helpful. You can build faster, onboard new engineers more quickly, and use the graph itself as a self-documenting technical specification.
Mixed-technical teams
In scenarios where product managers or operations leads need to audit or modify agent behavior, a visual canvas is far more accessible than a Python repository. This is a significant advantage for internal tools where the domain experts closest to the problem may not be comfortable writing code but understand the marketplace policies perfectly.
Rapid prototyping
You can move from a concept to a functional prototype in a single afternoon. The availability of pre-built connectors means you spend your time on the agent’s logic rather than writing boilerplate for API integrations.
Integration-heavy workflows
If the agent’s primary role is to connect disparate systems (e.g., pulling from a Shopify webhook, processing with an LLM, writing to Postgres, and notifying Slack), visual tools are purpose-built for the task. The thousands of connectors provided by platforms like Zapier represent substantial engineering effort you do not have to replicate.
Recognizing the ceiling
The signal that you have outgrown a visual tool usually relates to time allocation. If your team spends more time managing the layout of the graph, rerouting edges, and fighting the limitations of “Code” nodes than they do thinking about the agent’s reasoning, the abstraction has become a bottleneck. At that point, the overhead of the canvas exceeds its utility, and it is time to evaluate a code-driven or managed-platform approach.
C. Fully managed platforms (declarative)
There is a third path: a fully managed agent platform. Instead of writing orchestration code or arranging nodes on a canvas, you describe the desired behavior of the agent in a structured spec. The platform takes the spec, runs the resulting agent, and runs the production stack around it: execution, infrastructure, and lifecycle management.
This approach addresses the production gap by treating the non-functional requirements (testing, versioning, observability, deployment, model routing) as platform features rather than engineering tasks. In a code-driven or visual approach, those requirements often demand far more effort than the initial prototype. In a fully managed setup, you describe what the agent must achieve, and the platform materializes the how.
The spec is the creation surface. A useful analogy is SQL: it's declarative. You describe what you want and the database query planner figures out how to run the query. You focus on your data problem; the database focuses on indexes, statistics, referential integrity, atomic storage, and transactions. A managed-agent platform is the same posture applied to AI agents.
Logic is one example of this category. You write a structured specification of your problem and goals, and Logic generates a managed agent: a REST endpoint with well-typed schemas, automated test cases, immutable versioning, model routing, deployment surfaces (REST, MCP, web UI, email trigger, batch CSV), and full execution logging. Because the agent is managed, you can verify behavior against real inputs immediately rather than building a custom integration harness first.
Anthropic's Claude Managed Agents is another platform in this category, launched in 2026. Both are fully managed; the scope is different. Claude Managed Agents manages the container: Anthropic's runtime, the Claude model, and an open-ended task loop. Logic manages the agent itself: a typed, versioned, evaluated, observable production endpoint that plugs into the rest of your stack. For a generalist sandbox to hand to an end user, Claude Managed Agents is a fit. For a specific agent that needs to hit production with the six properties in place, a Logic-style platform is the closer match.
Precision still matters
While declarative platforms simplify operationalizing agents, they do not alleviate the need for precision. The guidance from the building blocks section, “write instructions like you’re onboarding a new hire,” remains the gold standard.
A high-level directive can produce a functional agent, but a detailed specification ensures reliability across edge cases.
Even this minimal spec produces a functioning agent that is fully tested, well-typed, observable, and production-ready in under 60 seconds:
The primary advantage of the declarative model is the production infrastructure that comes with the agent: observability, versioning, automated evals, model routing, and one-click rollback all materialize from the same spec. The typed API contract is generated alongside it, with the schema inferred from your specification.
You can use your agent from any system that can make HTTP calls:
import os
import requests
response = requests.post(
"https://api.logic.inc/v1/agents/product-classifier/executions",
headers={"Authorization": f"Bearer {os.environ['LOGIC_API_TOKEN']}"},
json={
"title": "Vintage Sony Walkman TPS-L2 1979 Original",
"description": "Original 1979 Sony Walkman in working condition. "
"Includes original headphones and leather case. "
"Minor cosmetic wear consistent with age."
}
)
classification = response.json()
# The response matches the spec's output schema exactly:
# {
# "category": "electronics",
# "subcategory": "portable audio",
# "is_restricted": false,
# "confidence": 0.98,
# "flags": []
# }In this model, the plain English specification is the single source of truth. But the output is not just “likely” to be JSON; it is mathematically constrained to match the schema derived from your spec. If the model attempts to return a malformed object or a missing field, the platform catches the error at the boundary. Your application code never has to handle unexpected data shapes.
This makes the interface between your deterministic engineered systems and the non-deterministic LLMs much safer and easier to integrate with.
Instructions for managed agents
In a managed-platform approach, the spec is the instruction. The same numbered-step, edge-case-documenting, threshold-defining patterns from the building blocks section apply directly. You write them into the spec the same way you’d write them into a system prompt, because the spec is the source material the platform uses to generate the agent’s behavior.
The difference is that the spec does double duty. In a code-driven system, your instructions are a string constant separate from your schema definitions, tool configurations, and deployment settings. In a managed-platform system, the spec is both the prompt and the configuration. Logic reads the spec and derives the input/output schema, generates test cases, and creates versioned deployments, all from the same document.
Loops and orchestration in managed agents
In a managed-agent platform, you can simply define the goal and the platform determines the iteration strategy.
When you describe a task that requires tool calls (like “look up prior classifications before classifying”), the platform handles the observe-reason-act cycle internally. It manages iteration limits, context history, and termination conditions. You don’t need to wire up a for loop or manage a message list. You describe the behavior you want, and the platform’s execution engine handles the mechanical orchestration.
Tools in managed agents
Tools in a managed-platform system come from three places.
The built-in tool suite. Logic ships with capabilities you can use out of the box: web search, image generation, reading PDFs and Office documents, filling PDF forms, audio processing, and others. If your agent needs to generate an image or search the web as part of its workflow, you describe that in the spec. No integration work required.
MCP integrations. For services outside the built-in suite, MCP support lets you connect external tools to your agents. This covers the long tail of integrations that any single platform's built-in tools won't reach.
Custom HTTP endpoints. If your agent needs a capability that isn't available through built-in tools or MCP, you expose it as an API endpoint. The spec calls it via HTTP. This is the escape hatch for proprietary internal services, legacy systems, or anything sufficiently custom that no platform would have it pre-built.
For most agentic tasks (classification, extraction, scoring, content generation), the built-in suite and MCP integrations cover what you need. The HTTP fallback exists for the cases where they don't, and it's worth noting that this pattern isn't unique to managed-agent platforms. In a code-driven system, you'd write the function. In a visual workflow, you'd wire up a code node or custom connector. The difference is that code-driven lets you build a new tool inline without standing up a separate service first. That's a genuine advantage when your agent needs something truly novel.
Regardless of where a tool comes from, the spec author focuses on what the agent needs and when it should use it. The platform handles invocation, error handling, retries, timeout management, and structured response parsing.
Guardrails in managed agents
The managed-platform model shifts much of the guardrail implementation from the developer to the platform.
Schema enforcement happens at the boundary automatically. Logic derives typed schemas from your spec and validates every input and output against them. Malformed data never reaches the model, and invalid outputs never reach your application.
Prompt injection defense is handled at the platform level. Because Logic controls the execution environment, it can apply input scanning and instruction hierarchy enforcement across all agents without requiring the spec author to implement these defenses individually.
Tool-level safety is enforced through the platform’s permission model rather than through allowlist code you write and maintain. The spec defines which tools the agent has access to, and the platform ensures those boundaries hold.
The tradeoff is transparency. In a code-driven system, you can read every line of your guardrail implementation. In a managed-platform system, you’re trusting the platform to apply those protections correctly. For teams that need to audit every security boundary in their own code, this delegation may not be acceptable. For teams that want production-grade safety without building the infrastructure, it removes a significant maintenance burden.
How a managed agent gets built
When you save a spec, Logic automatically kicks off about 25 parallel processes that mechanize the best practices discussed in this guide. Here’s an overview of some of the things Logic handles for you.
Automated schema inference
Logic derives technical constraints directly from the specification. For instance, a requirement stated as “confidence: 0-1 decimal score” results in the generation of a typed JSON schema where confidence is a float constrained between 0 and 1. This eliminates the need for separate schema definitions or Pydantic models; the technical contract is a direct derivative of the behavioral description.
Synthetic test generation
The platform analyzes the specification to identify boundary conditions and potential failure modes. It then generates a suite of synthetic test cases designed to probe these areas:
- Conflicting signals: Inputs that contain contradictory information (e.g., a “leather jacket” described as “synthetic”).
- Ambiguity: Descriptions that could fit multiple categories.
- Boundary conditions: Classification tasks where the confidence score might sit exactly at the threshold for human review.
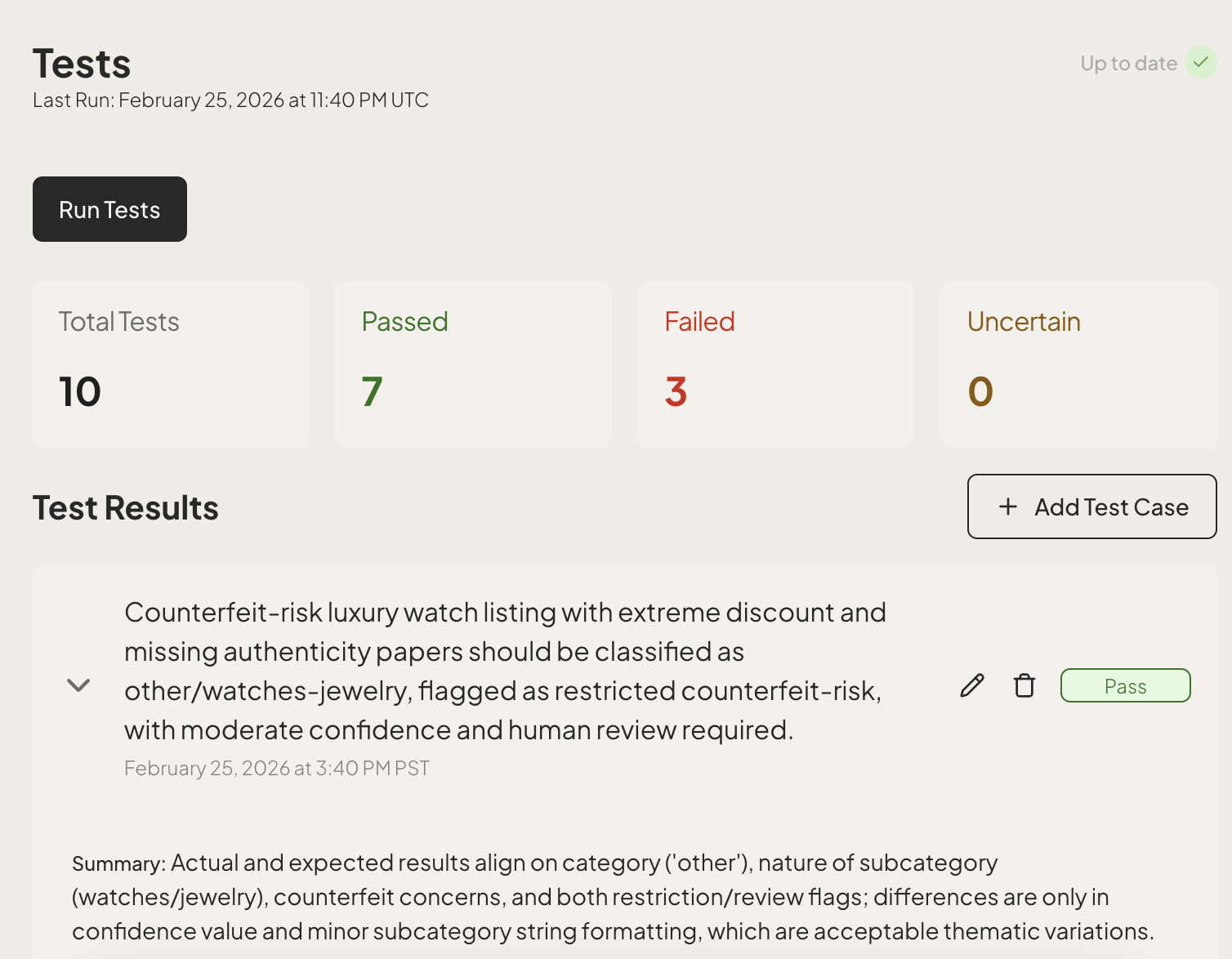
API and lifecycle management
Each specification creates a stable REST endpoint with built-in request and response validation. The platform manages the versioning of these endpoints automatically, even ensuring backward compatibility. Every save event generates a new immutable version, allowing for side-by-side comparison of execution results and one-click rollbacks if a change to the reasoning logic introduces unexpected regressions.
Every execution is logged with full context: inputs, outputs, versions, and latency. This logging isn’t just for debugging; any production run can be “promoted” to a permanent test case, allowing the agent’s performance to be measured against historical results, helping to prevent regressions.
Intelligent model routing
Logic can also abstract the choice of the underlying LLM through an intelligent routing layer. Requests are routed across providers, including OpenAI, Anthropic, and Google, based on the complexity and cost profile of the task.
For the product listing classifier, this means the platform might use a high-efficiency model like Gemini 3 Flash for clear-cut electronics, but dynamically shift to a high-reasoning model like GPT-5.4 or Claude Opus 4.6 when it encounters a complex policy violation check.
Automatic routing is the default. If you want explicit control, you can pin a specific model in the spec, set a reasoning level, or define a routing policy per task. The platform handles whichever choice you make.
Behavioral updates without redeployment
This architecture allows for “hot-swapping” the agent’s behavior. If a policy shift requires a new “vintage” subcategory, a domain expert can update the specification directly. Because the API contract remains stable, this change does not require a code deployment or a service restart. The platform runs existing test cases against the new specification draft, so you get an empirical “diff” of behavior before the new version is promoted to production.
And if any mistakes are made, it’s one-click to rollback to a known good version.
Measured accuracy lift from the managed harness
The managed harness measurably improves accuracy. On IFBench (a public benchmark for instruction-following accuracy), Logic scored 83.3%, a 7.1-point lift over the same underlying model called directly on the same inputs. The improvement comes from the harness around the model: structured spec parsing, schema enforcement at the boundary, synthetic regression tests on every save, dynamic learning from past executions, and model routing tuned per task.
Deployment surfaces
Once a spec ships, you don't have to choose just one way to call the agent. The same spec gets exposed through several surfaces at once:
- REST API is the default. Every agent gets a versioned endpoint with typed inputs and outputs.
- MCP server lets the agent be called from Claude, ChatGPT, Cursor, or any MCP-compatible client. Agents on Logic can also call out to external MCP servers (Linear, Jira, Notion, Shopify, and similar) for tools that aren't built in.
- Web UI generates a public-or-private execution interface from the spec, useful for sharing with non-engineers or running quick tests.
- Email trigger gives each agent a unique inbound address. Send the agent an email and it runs the spec on the email's contents.
- Batch CSV runs the agent against thousands of rows in parallel, with structured output returned as CSV.
Agents can also act on the world from inside the spec. The platform's built-in agent tools include sending email, making HTTP requests to internal services, and reading or writing to your knowledge library.
The testing workflow
Testing in a managed platform is a continuous loop rather than a pre-release hurdle. In Logic, test cases are aggregated from three distinct sources:
- Synthetic generation. When you create or update a spec, Logic generates test cases that probe edge cases you might not think of. The tests include realistic data combinations and scenarios that mirror real-world complexity.
- Manual creation. You add specific test cases for scenarios you care about: known edge cases, inputs that caused problems before, or examples that represent important business logic.
- Historical executions. Any production execution can be promoted to a permanent test case. When you see an input that represents an important scenario (or one that failed), you can quickly capture it as a regression test.
When you change the spec, tests are created automatically. This happens before you promote the new version to production, so you can catch regressions early.
The development cycle shifts from “write code, then test” to “edit spec, review results, then promote.” This ensures that every behavioral tweak is validated against a comprehensive golden set before it ever hits a user.
When a managed platform works well
In this approach, the platform handles the underlying orchestration, infrastructure, and lifecycle management for you, while you focus on the desired behavior of the agent.
Managed-platform agents can save your team weeks, months, and (sometimes) quarters of overhead. As you scale beyond your first few agents, the volume of agents and the frequency of their updates will outpace the growth of your application logic (database management, authentication, service communication). Operating a fleet of agents is a different problem from operating one, and the platform-level features (org-wide audit trail, RBAC, observability across every agent at once, model routing policies) start to matter more than the orchestration code itself.
As the lifecycle and domain expertise required for these two types of logic diverge, decoupling them is a critical architectural move: it ensures that a minor policy tweak in the agent gets its own dedicated, well tested, highly observable, versioned and logged deployment.
It also opens the way for ownership of the business logic (the agents) to shift toward domain experts who are not on the engineering team.
Recall the production gap from the code-driven section. Making the API call to the LLM is the easy part. But the required infrastructure (testing, versioning, and observability) dwarfs the agent logic itself. A managed-agent platform abstracts away this complexity.
If you’re happy with the choices that platform makes, it’s great. If you need more customizability, such a platform is likely not ideal.
Ideal use cases
Managed-platform agents are ideal in a few scenarios:
- Production engineering on a deadline. When an agent needs to ship with the six properties in place (reliable typed contracts, automated tests, versioning, observability, model independence, robust deployments) and the team doesn’t want to spend weeks or months building the harness around it. The infrastructure that separates a demo from production is what kills timelines, and a managed platform delivers it on day one.
- Fleet operations at scale. Once you’re running more than a few agents, the platform-level concerns (org-wide audit trail, RBAC, observability across every agent at once, model routing policies, cost tracking per agent) start to matter more than any individual agent’s orchestration code.
- Mixed-provider workloads. Routing across OpenAI, Anthropic, and Google based on task complexity is hard to do well from scratch. Managed agents come with provider-agnostic routing built in, so you can chase the cost, latency, and quality frontier without re-architecting the agent.
- Compliance-sensitive workloads. Logic is SOC 2 Type II and HIPAA certified, with immutable versioning and full execution logging on every run. The audit trail is generated automatically rather than built by hand.
- Evolving requirements. Tasks like classification and compliance checking where the rules change frequently and a domain expert (Compliance Officer, Product Lead, support manager) should be able to update behavior without filing a code-deploy ticket.
- Rapid production access. When the goal is a functional, validated agent in hours or days rather than weeks or months.
The operational trade-off
By adopting a managed-agent platform, you are delegating the orchestration (retries, prompt optimization, and iteration management) and infrastructure (log storage, versions, telemetry) to the platform. This is a deliberate trade-off.
If your task requires highly custom, non-standard control flows, the abstraction of a managed-agent platform may be too restrictive. These platforms are often cloud-hosted, which makes it challenging for teams with rigid on-prem data residency requirements to use them.
For the vast majority of agentic tasks, removing the overhead of orchestration and infrastructure is a major accelerant. It is often the difference between shipping a product and maintaining a proprietary platform.

Comparing the approaches: total cost of ownership
Choosing an approach isn’t just about how fast you can build a prototype. It’s about the full lifecycle: building it, shipping it, running it, and maintaining it over time.
The table below compares the three approaches across five dimensions that matter once you’re past the demo stage.
| Code-driven | Visual workflow | Fully managed | |
|---|---|---|---|
| Time to first prototype | Hours to days. Requires writing the LLM integration, schema definitions, and basic orchestration from scratch. Fast if you’ve done it before, slower the first time. | Minutes. Drag nodes, configure connectors, run a test. The fastest path to “something working.” | Minutes. Write the spec, get a working endpoint. Logic generates the schema, tests, and API in under 60 seconds. |
| Time to production-ready | Weeks to months. You need to build testing infrastructure, logging, versioning, deployment pipelines, and monitoring. The agent itself is the easy part. | Days to weeks. The agent works quickly, but production guardrails (testing, version control, rollback) require external tooling you’ll need to build or integrate. | Hours to days. Production infrastructure (typed APIs, automated tests, versioning, observability) comes with the platform. Your time goes into refining the spec and validating results. |
| Ongoing maintenance | High. You own every line of infrastructure code. Model updates, SDK changes, and new edge cases all require engineering work. Prompt changes go through the full deploy cycle unless you’ve built a separate system for it. | Medium. Platform handles infrastructure upkeep, but you maintain the graph, manage JSON exports for version control, and build external testing. Prompt changes are fast but unguarded without external tooling. | Low. Platform handles model routing, infrastructure, and testing infrastructure. Spec updates don’t require code deploys. Domain experts can iterate on behavior directly. |
| Infrastructure cost | Variable and self-managed. You pay for compute, LLM API calls, logging, storage, and monitoring. You also pay the engineering cost of building and running this infrastructure. Optimization is possible but requires effort. | Platform subscription plus LLM API costs. Some platforms include hosting; others (like self-hosted n8n) require your own infrastructure. Costs are more predictable but less optimizable. | Per-execution pricing. Infrastructure costs are bundled. Model routing can reduce LLM costs automatically. Less control over individual cost levers, but less engineering time spent on cost optimization. |
| Team requirements | Requires engineers with LLM experience for both building and maintaining the system. Domain experts can’t update agent behavior without engineering support unless you build a separate interface. | Lower barrier to entry. Engineers can build the initial workflow, and technically-inclined non-engineers can modify it. Custom logic still requires code. | Lowest engineering overhead for ongoing maintenance. Domain experts can update specs directly (with optional approval gates). Engineering effort shifts to integration and validation rather than infrastructure. |
Reading the tradeoffs
Each approach has a legitimate place depending on your team’s situation.
Code-driven gives you maximum control over every aspect of the system. If you’re building something genuinely novel, if you need to integrate with non-standard systems, or if your team has LLM engineering experience and wants to own the full stack, this is the right choice. The cost is that you’re also building the platform, not just the agent. For teams with the engineering depth and the runway to invest in infrastructure, that investment can pay off in flexibility.
Visual workflow tools lower the initial barrier and make agent logic visible to non-engineers. If your primary value is in connecting existing systems (pulling data from Shopify, processing with an LLM, pushing results to a database and Slack), and your agent’s logic stays relatively simple and linear, visual tools are purpose-built for the job. The cost surfaces as complexity grows: testing becomes manual, version control becomes awkward, and the graph itself becomes harder to reason about.
Fully managed platforms remove the infrastructure burden. You trade direct control over the execution engine for a dramatically faster path from idea to production, and lower ongoing maintenance. This approach works well when your agents follow established patterns (classification, extraction, scoring, review) and when you want domain experts to iterate on behavior without engineering tickets.
The wrong choice is the one made based on hype or habit rather than your actual constraints. A three-person startup with one engineer and a tight timeline should not be building LLM infrastructure from scratch. A team with deep ML expertise and non-standard orchestration requirements probably shouldn’t be locked into a platform’s assumptions.
Going further
You’ve got the six production properties covered, and you also know how to build your agent. The capabilities below aren’t required to ship, but teams that adopt them early tend to iterate faster and spend less over time.
Caching. If your agent handles classification, extraction, or data transformation, it’s probably seeing repeat inputs. Caching deterministic (or near-deterministic) responses means you skip the LLM call entirely for inputs you’ve processed before. The cost savings compound fast at volume, and latency drops to near zero for cache hits. In code-driven setups, you’ll wire this up yourself (Redis, a simple hash lookup, whatever fits). Visual workflow tools may or may not expose caching primitives. Managed-agent platforms like Logic handle caching by default: identical inputs return previous results with no new inference call, and you can disable it per-spec if you need every execution to run fresh. At 10,000+ executions per day, even a modest cache hit rate cuts your inference bill meaningfully.
Streaming. For user-facing agents, streaming partial responses cuts perceived latency dramatically. Your user sees tokens arrive in real time instead of staring at a spinner. Batch processing agents don’t need this. If your agent talks to humans, it probably does. Code-driven: most LLM SDKs support streaming natively. Visual workflow: depends on the tool. Fully managed: not all platforms support streaming yet. Logic currently handles synchronous and batch execution; streaming isn’t available today. Check whether your platform supports it before committing to a streaming UX.
Dynamic learning and long-term memory. Dynamic learning means the agent indexes its own past executions and retrieves similar examples as few-shot context at inference time. The agent gets better as it processes more inputs.
- Code-driven: you’ll build the indexing, similarity search, and retrieval logic yourself. This is non-trivial.
- Visual workflow tools: This capability is generally non-existent in visual graph-based tools.
- Fully managed: Logic’s implementation semantically indexes every input/output pair and retrieves a minimum of three historical examples per execution to prevent error propagation. Logic is also building long-term memory capabilities that will go beyond semantic indexing, eventually giving agents the ability to retain and recall context across sessions and evolve their behavior over time.
Multimodal support. Text-only agents can’t touch document processing, form filling, visual QA, or audio workflows. If your use case involves PDFs, Office documents, images, or voice, you need multimodal input handling from the start. Retrofitting it later is painful. The good news is most frontier models are multimodal by default at this point in time.
Real-world examples
Garmentory: content moderation at marketplace scale
Garmentory connects over 1,000 independently owned boutiques to online shoppers. Until last year, every product imported into the marketplace had to be moderated by a human before it could go live. That meant reviewing 10 to 20 data points per item: title, category, size, color, description, final sale status, made-to-order flag, and more.
Six full-time contractors handled moderation. A good moderator could process about 200 products per day, but quality degraded as fatigue set in. Realistic throughput at acceptable quality was roughly 1,500 products per day across the team. During busy seasons, 5,000 to 10,000 products arrived per week. Backlogs stretched to 4-5 days. Vendors got anxious waiting for listings; some items were “stale” before they ever hit the site.
With Logic, Garmentory turned their 10-page moderation SOP into 3-4 discrete agent components. Each one was tested independently against historical human-moderated products. Implementation took a single person under a week, with no changes to their existing stack. Garmentory already consumed APIs from 20+ services. This was just another one.
The results:
- Moderation time: 4-5 day backlog to 48 seconds per product
- Weekly volume: 5,000 to 15,000-20,000 products
- Active inventory: $150M to $250-300M
- Cost per product: ~25 cents to ~2-3 cents
- Quality: Matched or exceeded human moderator accuracy on every batch tested
- Business impact: Best financial quarter in company history
“A year ago, we were using almost no AI. Today, we’re exploring using it in every part of our business. Logic made that jump possible.”
Sunil Gowda, CEO, Garmentory
Getting started
Before you pick an approach, take some time to consider:
- What’s your timeline? If you need something in production this week, building infrastructure from scratch isn’t realistic. If you have months and a platform team, you have more options.
- What are your team’s strengths? Deep LLM engineering experience? Full control might serve you well. Stretched thin and need to ship? A platform that handles infrastructure lets you focus on the agent’s business rules.
- Where’s the complexity in your problem? If it’s in the reasoning (what the agent decides), a managed platform or visual tools can handle it. If it’s in the orchestration (how steps connect), code gives you more control.
- How often will behavior change? If domain experts need to tweak the agent regularly, an approach that requires code deploys for every change will slow you down.
With that context, here are four starting points:
If you’re just learning: Build one agent end to end using whichever approach interests you. Get it working. Then evaluate what you built against the six production properties. You’ll quickly feel which gaps are easy to close yourself and which ones will eat your roadmap.
If you have a working prototype: Run it through the production readiness checklist. Be honest about where the gaps are. Most prototypes nail the happy path but fall short on testing, observability, and versioning. The checklist will tell you how much work sits between where you are and where production needs to be.
If you’re stuck in framework complexity: Ask yourself: are you spending more time fighting the framework than building agent logic? If yes, evaluate whether a managed-platform approach or direct API calls would reduce your maintenance burden. Switching costs are real, but so is the ongoing tax of working around abstractions that don’t fit your problem.
If you’re ready to ship: Pick the approach that matches your constraints, not the one that sounds most impressive.
If you want to try the managed-platform approach, Logic lets you go from spec to production endpoint in under 60 seconds. Start with a free trial, bring a real use case, and see how your agent scores on the six properties before committing to anything. Most teams have their first agent live the same day.
Logic is SOC 2 Type II and HIPAA certified, with 99.999% achieved uptime over the last 90 days. Try it free at logic.inc or see current pricing at logic.inc/pricing.
About Logic
Logic is a managed-agent platform for building and operating fleets of production AI agents. You describe what the agent should do in a structured spec, and Logic returns a managed agent: typed REST APIs, synthetic tests on every save, immutable versioning with one-click rollback, multi-provider model routing, full execution logging, and deployment surfaces (REST, MCP, web UI, email, batch CSV) generated from the same spec. No infrastructure to build or run. The platform is SOC 2 Type II and HIPAA certified, handles over 250,000 agent executions monthly, and has held 99.999% uptime over the last 90 days. See how it works at logic.inc.
Related resources
- Garmentory case study: content moderation at marketplace scale
- Logic documentation
- Logic pricing
- Logic security and compliance
- How Logic works
Frequently asked questions
What is an AI agent?
An AI agent is a system that receives a task, figures out what to do, and does it. It perceives context, reasons about it, uses tools to interact with external systems, and produces structured output or takes real actions. That's what separates it from a chatbot (which answers questions in a dialogue) or a workflow (which follows a fixed decision path). The agents that create the most value in production right now aren't flashy. They're document processors, content moderators, classifiers, and data extractors.
What makes an AI agent production-ready?
Six properties: reliable responses (typed input/output schemas enforced at the boundary), testability (automated deterministic and probabilistic tests that run before every deployment), version control (immutable versioned bundles of the full agent config with one-click rollback), observability (full execution tracing of every input, output, and tool call), model independence (architecture decoupled from any single provider so you can balance cost, latency, and quality), and robust deployments (behavioral updates ship independently of application code, with support for shadow and canary rollouts). Building all six yourself is doable but time-consuming. Managed-agent platforms like Logic provide them out of the box, so your team can focus on the agent's behavior rather than the infrastructure around it.
What are the main approaches to building AI agents?
Three approaches dominate. Code-driven: you write orchestration logic in Python or TypeScript, giving you maximum control but also maximum infrastructure burden. Visual workflow: you compose nodes on a canvas using tools like n8n or Zapier, which is fast to prototype but can get unwieldy as logic grows. Fully managed: you describe the agent's behavior in a natural language specification and the platform handles infrastructure, testing, and deployment. Each makes different tradeoffs around control, speed, and ongoing maintenance. The right choice depends on your team's strengths and the complexity of your problem.
Should I use a framework like LangChain?
Frameworks can speed up prototyping, but they often add complexity in production. When an agent fails, you end up debugging through layers of third-party code rather than your own logic. Some teams call this the "framework tarpit": you adopt it to save time, then spend more time working around its opinions than you would've spent writing the orchestration yourself. If you want the productivity boost without the abstraction tax, a managed-agent platform offers another path: you describe what the agent should do in a structured spec, and the platform runs the agent and handles orchestration, testing, versioning, observability, and deployment for you. You keep full control over the agent's behavior without managing the framework's lifecycle or the production stack around it.
How do you test AI agents?
Two layers. Deterministic tests check the invariants: does the JSON have the required keys, is the intent field classified correctly, did the agent refuse a jailbreak attempt? These are binary pass/fail and you can run them on every commit. Probabilistic evals measure performance against a golden dataset of 50 to 100 historical inputs where the ideal answer is known, using metrics like context recall, faithfulness, and semantic similarity. If your new version scores lower than the last one, you have a regression. The key insight is to test structure, not prose, because structure is a deterministic property of a non-deterministic output. Managed-agent platforms like Logic generate both test types automatically from your agent's specification, so you don't have to build the test harness from scratch.
What is AI agent observability?
Agent observability is the ability to see exactly what an agent did, and why, for any given execution: the input it received, the model version that ran, the system prompt and tool definitions active at the time, every tool call it made, the responses it got back, the intermediate reasoning, the final output, and the latency at every step. Traditional software fails loudly with an exception and a stack trace pointing to a line of code. An AI agent usually fails quietly by returning confident but wrong output without throwing anything. And because runs are non-deterministic, you can't reliably re-run an input locally and reproduce the bug. Without a captured execution trace from the moment of failure, debugging an agent is guesswork. Managed-agent platforms log this trace for every execution automatically; in a code-driven setup, you build the tracing yourself.
What is AI agent orchestration?
Orchestration is the layer that decides what an agent does next: when to call a tool, when to stop looping, how to handle a failure, when to escalate to a human, how to manage context across multiple steps. In a code-driven setup, you write the orchestration yourself, usually as a for loop with tool dispatch and retry logic. In a visual workflow, orchestration is the graph of nodes you arrange on the canvas. In a fully managed platform, orchestration is a platform feature: you describe the goal in the spec and the platform handles retries, iteration limits, tool sequencing, and context management.
Should I build my own AI agent or use a platform?
That depends on what you're optimizing for. Building from scratch gives you total control and no vendor dependency, but you're also signing up for months of infrastructure work: orchestration, testing, versioning, deployment, observability, and ongoing maintenance. Off-the-shelf platforms give you speed but can limit customization. A managed-agent platform splits the difference: you define the agent's behavior in detail (what it does, how it responds, what tools it uses), and the platform runs the agent and the production stack around it. You own the "what"; the platform owns the "how." Logic works this way: write a spec, get a managed agent with a versioned, tested, production-ready REST API, with no infrastructure to build or run.
What are AI agent guardrails?
Guardrails prevent your agent from taking unintended actions. They operate at three layers. Input guardrails filter before the model reasons: relevance classifiers reject off-topic requests, prompt injection detection catches attempts to override instructions, and PII filtering strips sensitive data. Output guardrails validate after the model responds: schema enforcement ensures structural correctness, and a secondary "critic" model can catch logical errors that pass structural checks. Tool-level guardrails enforce least privilege: restricting which tools the agent can call, requiring human approval for destructive operations, and enforcing rate limits. Managed-agent platforms enforce many of these by default because the spec itself defines the boundaries of acceptable behavior. These aren't optional. An agent that hallucinates doesn't just give you a wrong answer; it might send a real email, delete real data, or charge a real credit card.
How much does it cost to run an AI agent in production?
It depends on approach and scale. Code-driven setups require infrastructure investment on top of LLM API costs (typically $0.01 to $0.10 per call depending on the model and task complexity). Visual workflow tools charge a subscription fee plus API costs. Managed-agent platforms like Logic charge per execution. At volume, techniques like caching (skipping inference entirely for repeat inputs), tiered model routing (using cheaper models for simple tasks), and batching reduce costs significantly. One marketplace using a managed-platform approach cut per-product moderation costs from roughly 25 cents to 2-3 cents.
Recommended next reads
AI Agent Infrastructure: What It Takes to Run Agents in Production
Production AI agents need infrastructure most teams underestimate. Learn the six concerns separating demos from production and when to offload.
LLM Agents in Production: The Infrastructure Gap Between Demo and Deployment
Most teams stall getting LLM agents in production. Logic eliminates the infrastructure gap with typed APIs, testing, and versioning so you ship in minutes.
Agentic AI Testing: Own the Infrastructure or Offload It
Agentic AI testing requires probabilistic evaluation, version control, and execution logging. Learn when to build the infrastructure and when to offload it.
6 best AI agent platforms April 2026
Find the 6 best AI agent platforms to try in April 2026. Compare Logic, LangChain, CrewAI, and more for production-ready agent development.
LangChain Alternatives for Production AI Teams in 2026
A look at LangChain alternatives that hold up past prototype: Logic, LlamaIndex, Haystack, CrewAI, and PydanticAI. Where each one fits, what they leave to your team, and how to decide between owning the orchestration layer or handing it off.